快速入门Graph
本手册将逐步指导您使用 NebulaGraph,包括:
- 安装
- 数据建模
- 增删改查
- 批量插入
- 数据导入工具
安装Graph
我们推荐使用 Graph。
除了使用 Docker,您还可以选择Graph 方式安装 NebulaGraph。
如果您在安装过程中遇到任何问题,可以前往 NebulaGraph Graph 提问,我们有专门的值班开发人员为您解答问题。
数据建模Graph
在本手册中,我们将通过下图所示的数据集向您展示如何使用 NebulaGraph 数据库。
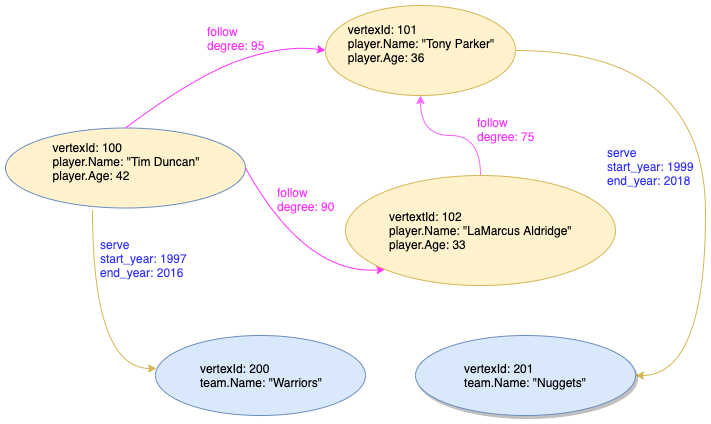
上图中有两个标签(player、team)以及两条边类型(serve、follow)。
创建并使用图空间Graph
NebulaGraph 中的图空间类似于传统数据库中创建的独立数据库,例如在 MySQL 中创建的数据库。 首先,您需要创建一个图空间并使用 (use) 它,然后才能执行其他操作。
您可以通过以下步骤创建并使用图空间:
-
检查集群机器状态:
nebula> SHOW HOSTS; ================================================================================================ | Ip | Port | Status | Leader count | Leader distribution | Partition distribution | ================================================================================================ | 192.168.8.210 | 44500 | online | | | | ------------------------------------------------------------------------------------------------ | 192.168.8.211 | 44500 | online | | | | ------------------------------------------------------------------------------------------------状态
online表示存储服务进程storaged已经成功连接上元数据服务进程metad。 -
输入以下语句创建图空间:
nebula> CREATE SPACE basketballplayer (partition_num=10, replica_factor=1);这里:
partition_num:指定一个副本中的分区数。通常为全集群硬盘数量的 5 倍。
-
replica_factor:指定集群中副本的数量,通常生产环境为 3,测试环境可以为 1。由于采用多数表决原理,因此需为奇数。你可以通过
SHOW HOSTS命令检查机器和 partition 分布情况:nebula> SHOW HOSTS; ============================================================================================================= | Ip | Port | Status | Leader count | Leader distribution | Partition distribution | ============================================================================================================= | 192.168.8.210 | 44500 | online | 8 | basketballplayer: 8 | test: 8 | ------------------------------------------------------------------------------------------------------------- | 192.168.8.211 | 44500 | online | 2 | basketballplayer: 2 | test: 2 | -------------------------------------------------------------------------------------------------------------若发现机器都已在线 (online),但 Leader distribution 分布不均(如上),则可以通过命令 (
BALANCE LEADER) 来触发 partition 重分布:nebula> BALANCE LEADER; ============================================================================================================= | Ip | Port | Status | Leader count | Leader distribution | Partition distribution | ============================================================================================================= | 192.168.8.210 | 44500 | online | 5 | basketballplayer: 5 | test: 5 | ------------------------------------------------------------------------------------------------------------- | 192.168.8.211 | 44500 | online | 5 | basketballplayer: 5 | test: 5 | -------------------------------------------------------------------------------------------------------------具体解释可以见Graph。
-
输入以下语句来指定使用的图空间:
nebula> USE basketballplayer; -
现在,您可以通过以下语句查看刚创建的空间:
nebula> SHOW SPACES;返回以下信息:
======== | Name | ======== | basketballplayer | --------
定义数据的 SchemaGraph
在 NebulaGraph 中,我们将具有相同属性的点分为一组,该组即为一个标签。CREATE TAG 语句定义了一个标签,标签名称后面的括号中是标签的属性和属性类型。CREATE EDGE 语句定义边类型,类型名称后面的括号中是边的属性和属性类型。
您可以通过以下步骤创建标签和边类型:
-
输入以下语句创建 player 标签:
nebula> CREATE TAG player(name string, age int); -
输入以下语句创建 team 标签:
nebula> CREATE TAG team(name string); -
输入以下语句创建 follow 边类型:
nebula> CREATE EDGE follow(degree int); -
输入以下语句创建 serve 边类型:
nebula> CREATE EDGE serve(start_year int, end_year int); -
现在,您可以查看刚刚创建的标签和边类型。
5.1 要获取刚创建的标签,请输入以下语句:
nebula> SHOW TAGS;返回以下信息:
============ | Name | ============ | player | ------------ | team | ------------5.2 要显示刚创建的边类型,请输入以下语句:
nebula> SHOW EDGES;返回以下信息:
========== | Name | ========== | serve | ---------- | follow | ----------5.3 要显示 player 标签的属性,请输入以下语句:
nebula> DESCRIBE TAG player;返回以下信息:
=================== | Field | Type | =================== | name | string | ------------------- | age | int | -------------------5.4 要获取 follow 边类型的属性,请输入以下语句:
nebula> DESCRIBE EDGE follow;返回以下信息:
===================== | Field | Type | ===================== | degree | int | ---------------------
创建索引Graph
您可以使用 CREATE INDEX 为已有 Tag/Edge-type 创建索引。
nebula> CREATE TAG INDEX player_index_0 on player(name);
上述语句在所有标签为 player 的顶点上为属性 name 创建了一个索引。
索引会影响写性能,第一次批量导入的时候,建议先导入数据,再批量重建索引;不推荐带索引批量导入,这样写性能会非常差。
详情参看Graph。
增删改查Graph
插入数据Graph
您可以根据Graph中的关系插入点和边数据。
插入点Graph
INSERT VERTEX 语句通过指定点的标签、属性、点 ID 和属性值来插入一个点。
您可以通过以下语句插入点:
nebula> INSERT VERTEX player(name, age) VALUES 100:("Tim Duncan", 42);
nebula> INSERT VERTEX player(name, age) VALUES 101:("Tony Parker", 36);
nebula> INSERT VERTEX player(name, age) VALUES 102:("LaMarcus Aldridge", 33);
nebula> INSERT VERTEX team(name) VALUES 200:("Warriors");
nebula> INSERT VERTEX team(name) VALUES 201:("Nuggets");
nebula> INSERT VERTEX player(name, age) VALUES 121:("Useless", 60);
注意:
-
在上面插入的点中,关键词
VALUES之后的数字是点的 ID(缩写为VID, int64)。每个图空间中的VID必须是唯一的。 -
最后插入的点(VID: 121)将在下文Graph部分中删除。
-
如果您想一次批量插入同类型的点,可以执行以下语句:
nebula> INSERT VERTEX player(name, age) VALUES 100:("Tim Duncan", 42), \ 101:("Tony Parker", 36), 102:("LaMarcus Aldridge", 33);反除号
\用于实现多行语句。
插入边Graph
INSERT EDGE 语句通过指定边类型名称、属性、起始点VID和目标点VID以及属性值来插入边。
您可以通过以下语句插入边:
nebula> INSERT EDGE follow(degree) VALUES 100 -> 101:(95);
nebula> INSERT EDGE follow(degree) VALUES 100 -> 102:(90);
nebula> INSERT EDGE follow(degree) VALUES 102 -> 101:(75);
nebula> INSERT EDGE serve(start_year, end_year) VALUES 100 -> 200:(1997, 2016);
nebula> INSERT EDGE serve(start_year, end_year) VALUES 101 -> 201:(1999, 2018);
同样的:如果您想一次批量插入多条同类型的边,可以执行以下语句:
nebula> INSERT EDGE follow(degree) VALUES 100 -> 101:(95), 100 -> 102:(90), 102 -> 101:(75);
读取数据Graph
在 NebulaGraph 中插入数据后,您可以从图空间中查询到之前已经插入的数据。
FETCH PROP ON 语句从图空间检索数据。如果要获取点的数据,则必须指定点的标签和点 VID;如果要获取边数据,则必须指定边的类型、起始点 VID 和目标点 VID。
例如,要获取 VID 为 100 的选手的数据,请输入以下语句:
nebula> FETCH PROP ON player 100;
返回以下信息:
=======================================
| VertexID | player.name | player.age |
=======================================
| 100 | Tim Duncan | 42 |
---------------------------------------
例如,要获取 VID 100 和 VID 200 之间的类型为 serve 的边上的属性,请输入以下语句:
nebula> FETCH PROP ON serve 100 -> 200;
返回以下信息:
=============================================================================
| serve._src | serve._dst | serve._rank | serve.start_year | serve.end_year |
=============================================================================
| 100 | 200 | 0 | 1997 | 2016 |
-----------------------------------------------------------------------------
更新数据Graph
您可以更新刚插入的点和边数据。
更新点数据Graph
UPDATE VERTEX 语句用于更新点的属性。
指定要更新的点 VID,然后在等号右侧为其分配新值来更新点的全部或者部分属性。
以下示例说明如何将 VID 100 的属性 name 从 Tim Duncan 更改为 Tim。
输入以下语句更新 name 值:
nebula> UPDATE VERTEX 100 SET player.name = "Tim";
要检查 name 值是否已更新,请输入以下语句:
nebula> FETCH PROP ON player 100;
返回以下信息:
=======================================
| VertexID | player.name | player.age |
=======================================
| 100 | Tim | 42 |
---------------------------------------
更新边数据Graph
类似的,UPDATE EDGE 语句用于更新边的属性。
通过指定边的起始点 VID 和目标点 VID,然后在等号右侧为其分配新值来更新边的属性。
以下示例展示了如何更改 VID 100 和 VID 101 之间,类型为 follow 的边的属性。
现在,我们将 degree 的值增加 1。
nebula> UPDATE EDGE 100 -> 101 OF follow SET degree = follow.degree + 1;
要检查 degree 的值是否已更新,请输入以下语句:
nebula> FETCH PROP ON follow 100 -> 101;
返回以下信息:
============================================================
| follow._src | follow._dst | follow._rank | follow.degree |
============================================================
| 100 | 101 | 0 | 96 |
------------------------------------------------------------
UPSERTGraph
UPSERT 用于插入新的顶点或边或更新现有的顶点或边。如果顶点或边不存在,则会新建该顶点或边。UPSERT 是 INSERT 和 UPDATE 的组合。
例如:
nebula> INSERT VERTEX player(name, age) VALUES 111:("Ben Simmons", 22); -- 插入一个新点。
nebula> UPSERT VERTEX 111 SET player.name = "Dwight Howard", player.age = $^.player.age + 11 WHEN $^.player.name == "Ben Simmons" && $^.player.age > 20 YIELD $^.player.name AS Name, $^.player.age AS Age; -- 对该点进行 UPSERT 操作。
=======================
| Name | Age |
=======================
| Dwight Howard | 33 |
-----------------------
详情查看 Graph。
删除数据Graph
删除点Graph
DELETE VERTEX 语句通过指定点 VID 来删除点。同时也会删除该点的所有标签,以及和该点相邻的所有入边和出边。
要删除 VID 121 的点,请输入以下语句:
nebula> DELETE VERTEX 121;
要检查是否删除了该点,请输入以下语句;
nebula> FETCH PROP ON player 121;
Execution succeeded (Time spent: 1571/1910 us)
上面返回结果为空,表示查询操作成功,但是由于数据已被删除,未能从图空间中查询到任何数据。
删除边Graph
您可以从图空间中删除任何边。DELETE EDGE 语句通过指定边的类型以及起始点 VID 和目标点 VID 来删除边。
要删除 VID 100 和 VID 200 之间的类型为 follow 的边,请输入以下语句:
nebula> DELETE EDGE follow 100 -> 200;
其他Graph
查询示例Graph
本节提供了更多查询示例供您参考。
示例1Graph
查询球员 VID 100 关注 (follow) 的其他球员。
输入以下语句:
nebula> GO FROM 100 OVER follow;
返回以下信息:
===============
| follow._dst |
===============
| 101 |
---------------
| 102 |
---------------
示例2Graph
查询球员 VID 100 关注的球员,被关注球员年龄需大于 35 岁。
返回其姓名和年龄,并取别名为 Teammate 和 Age。
输入以下语句:
nebula> GO FROM 100 OVER follow WHERE $$.player.age >= 35 \
YIELD $$.player.name AS Teammate, $$.player.age AS Age;
返回以下信息:
=====================
| Teammate | Age |
=====================
| Tony Parker | 36 |
---------------------
这里:
YIELD指定希望从查询中返回的结果。$$表示边上的目的点。\表示换行符。
示例3Graph
查询球员 100 关注的球员所效力的球队。
有两种方法可获得相同的结果:
-
使用
管道(|)来组合两个查询语句nebula> GO FROM 100 OVER follow YIELD follow._dst AS id | \ GO FROM $-.id OVER serve YIELD $$.team.name AS Team, \ $^.player.name AS Player;返回如下信息:
=============================== | Team | Player | =============================== | Nuggets | Tony Parker | -------------------------------这里:
$^表示边的起始点。|表示管道。$-表示输入流。上一个查询的输出(id)作为下一个查询的输入($-.id)。 -
使用
自定义的变量来组合两个查询语句nebula> $var = GO FROM 100 OVER follow YIELD follow._dst AS id; \ GO FROM $var.id OVER serve YIELD $$.team.name AS Team, \ $^.player.name AS Player;返回以下信息:
=============================== | Team | Player | =============================== | Nuggets | Tony Parker | -------------------------------
当一条组合语句被整体提交给服务器后,该语句内的自定义变量就已结束生命周期。
示例 4Graph
如果您已为数据创建索引且重构索引,则可以使用 LOOKUP ON 关键字进行属性查询。
请参考Graph创建索引。
如下示例返回名称为 Tony Parker,标签为 player 的顶点。
nebula> LOOKUP ON player WHERE player.name == "Tony Parker" \
YIELD player.name, player.age;
=======================================
| VertexID | player.name | player.age |
=======================================
| 101 | Tony Parker | 36 |
---------------------------------------
详情参考 Graph。
批量执行Graph
通常测试时需要执行多条数据来准备环境,可以将所有语句放入一个 .ngql 文件中,如下所示。
CREATE SPACE basketballplayer(partition_num=10, replica_factor=1);
USE basketballplayer;
CREATE TAG player(name string, age int);
CREATE TAG team(name string);
CREATE EDGE follow(degree int);
CREATE EDGE serve(start_year int, end_year int);
在服务器:
$ cat schema.ngql | ./bin/nebula -u <user> -p <password>
或者 Docker 中
$ cat basketballplayer.ngql | sudo docker run --rm -i --network=host \
vesoft/nebula-console:nightly --addr=<127.0.0.1> --port=<3699>
这里:
- 必须将 --addr 和 --port 更改为您自己的 IP 地址和端口号。
- 可以在Graph下载
basketballplayer.ngql文件。
批量导入Graph
如果您要插入数百万条记录,建议使用 Graph。
最后Graph
如果您在使用 NebulaGraph 的过程中遇到任何问题,请前往我们的 Graph 提问,将有专门的值班开发人员为您解答问题。
如果您完成了本手册的全部操作,认为 NebulaGraph 是一款值得尝试的图数据库产品,恳请移步 Graph 留下您珍贵的一颗星,这将鼓舞我们继续向前。