Storage服务Graph
NebulaGraph的存储包含两个部分,一个是Meta相关的存储,称为Meta服务,另一个是具体数据相关的存储,称为Storage服务。Meta服务运行在nebula-metad进程中,Storage服务运行在nebula-storaged进程中。本文仅介绍Storage服务的架构设计。
优势Graph
- 高性能(自研KVStore)
- 易扩展(Shared-nothing架构)
- 强一致性(Raft)
- 高可用性(Raft)
- 支持向第三方系统进行同步(例如Graph)
Storage服务架构Graph
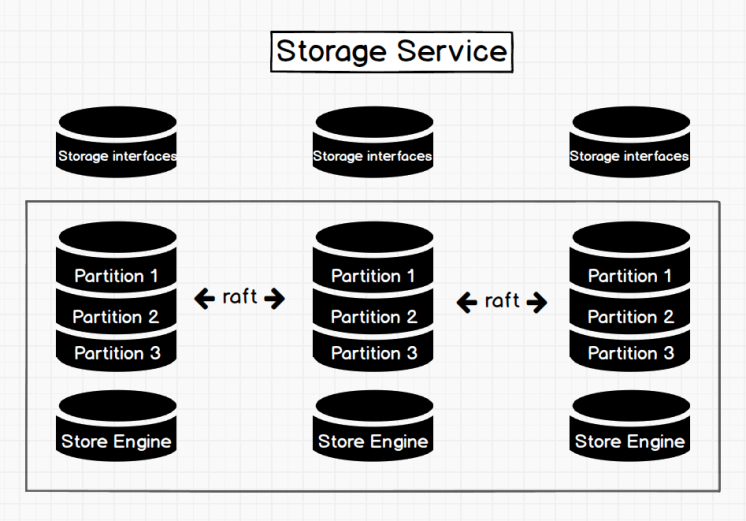
Storage服务是由nebula-storaged进程提供的,您可以根据场景配置nebula-storaged进程数量,例如测试环境1个,生产环境3个。
所有nebula-storaged进程构成了基于Raft协议的集群,整个服务架构可以分为三层,从上到下依次为:
- Storage interface层
Storage服务的最上层,定义了一系列和图相关的API。API请求会在这一层被翻译成一组针对Graph的KV操作,例如:
-
getNeighbors:查询一批点的出边或者入边,返回边以及对应的属性,并且支持条件过滤。-
insert vertex/edge:插入一条点或者边及其属性。-
getProps:获取一个点或者一条边的属性。正是这一层的存在,使得Storage服务变成了真正的图存储,否则Storage服务只是一个KV存储服务。
- Consensus层
Storage服务的中间层,实现了Graph,保证强一致性和高可用性。
- Store Engine层
Storage服务的最底层,是一个单机版本地存储引擎,提供对本地数据的
get、put、scan等操作。相关接口存储在KVStore.h和KVEngine.h文件,您可以根据业务需求定制开发相关的本地存储插件。
下文将基于架构介绍Storage服务的部分特性。
自研KVStoreGraph
NebulaGraph使用自行开发的KVStore,而不是其他开源KVStore,原因如下:
- 需要高性能KVStore。
- 需要以库的形式提供,实现高效计算下推。对于强Schema的NebulaGraph来说,计算下推时如何提供Schema信息,是高效的关键。
- 需要数据强一致性。
基于上述原因,NebulaGraph使用RocksDB作为本地存储引擎,实现了自己的KVStore,有如下优势:
- 对于多硬盘机器,NebulaGraph只需配置多个不同的数据目录即可充分利用多硬盘的并发能力。
-
由Meta服务统一管理所有Storage服务,可以根据所有分片的分布情况和状态,手动进行负载均衡。
Note
不支持自动负载均衡是为了防止自动数据搬迁影响线上业务。
- 定制预写日志(WAL),每个分片都有自己的WAL。
- 支持多个图空间,不同图空间相互隔离,每个图空间可以设置自己的分片数和副本数。
数据存储格式Graph
图存储的主要数据是点和边,NebulaGraph将点和边的信息存储为key,同时将点和边的属性信息存储在value中,以便更高效地使用属性过滤。
由于NebulaGraph 2.0的数据存储格式在1.x的基础上做了修改,下文将在介绍数据存储格式时同时介绍不同版本的差异。
- 点数据存储格式

字段 说明 Typekey类型。长度为1个字节。 PartID数据分片编号。长度为3个字节。此字段主要用于Storage负载均衡(balance)时方便根据前缀扫描整个分片的数据。 VertexID点ID。当点ID类型为int时,长度为8个字节;当点ID类型为string时,长度为创建图空间时指定的 fixed_string长度。TagID点关联的标签ID。长度为4个字节。
- 边数据存储格式

字段 说明 Typekey类型。长度为1个字节。 PartID数据分片编号。长度为3个字节。此字段主要用于Storage负载均衡(balance)时方便根据前缀扫描整个分片的数据。 VertexID点ID。前一个 VertexID在出边里表示起始点ID,在入边里表示目的点ID;后一个VertexID出边里表示目的点ID,在入边里表示起始点ID。Edge Type边的类型。大于0表示出边,小于0表示入边。长度为4个字节。 Rank用来处理两点之间有多个同类型边的情况。您可以根据自己的需求进行设置,例如存放交易时间、交易流水号等。长度为8个字节, PlaceHolder占位符,预留给TOSS(Transaction On Storage Side)功能使用。长度为1个字节。
Note
2.0和1.x的差异如下:
- 1.x中,点和边的Type值相同,而在2.0中进行了区分,即在物理上分离了点和边,方便快速查询某个点的所有标签。
- 1.x中,VertexID仅支持int类型,而在2.0中新增了string类型。
- 2.0中取消了1.x中的保留字段Timestamp。
- 2.0中边数据新增字段PlaceHolder。
- 2.0中修改了索引的格式,以便支持范围查询。
属性说明Graph
对于点或边的属性信息,NebulaGraph会将属性信息编码后按顺序存储,由于属性的长度是固定的,查询时可以根据偏移量快速查询。NebulaGraph使用强类型Schema,所以在解码之前,需要先从Meta服务中查询具体的Schema信息。同时为了支持在线变更Schema,在编码属性时,会加入对应的Schema版本信息。
数据分片Graph
目前NebulaGraph的分片策略采用静态 Hash的方式,即对点ID进行取模操作,同一个点的所有标签、出边和入边信息都会存储到同一个分片,这种方式极大地提升了查询效率。
对于在线图查询来说,最常见的操作便是从一个点开始向外拓展(广度优先),查询一个点的出边或者入边是最基本的操作,同时可能会根据属性进行过滤,NebulaGraph通过将属性与点边存储在一起,保证了整个操作的高效。
Note
创建图空间时需指定分片数量,分片数量设置后无法修改,建议设置时提前满足业务将来的扩容需求。
RaftGraph
由于Storage服务需要支持集群分布式架构,所以基于Raft协议实现了Multi Group Raft,即每个分片的所有副本共同组成一个Raft group,其中一个副本是leader,其他副本是follower,从而实现强一致性和高可用性。Raft的部分实现如下。
Multi Group RaftGraph
由于Raft日志不允许空洞,NebulaGraph使用Multi Group Raft缓解此问题,分片数量较多时,可以有效提高NebulaGraph的性能。但是分片数量太多会增加开销,例如Raft group内部存储的状态信息、WAL文件,或者负载过低时的批量操作。
实现Multi Group Raft有2个关键点:
- 共享Transport层
每一个Raft group内部都需要向对应的peer发送消息,如果不能共享Transport层,会导致连接的开销巨大。
- 共享线程池
如果不共享一组线程池,会造成系统的线程数过多,导致大量的上下文切换开销。
批量(Batch)操作Graph
NebulaGraph中,每个分片都是串行写日志,为了提高吞吐,写日志时需要做批量操作,但是由于NebulaGraph利用WAL实现一些特殊功能,需要对批量操作进行分组,这是NebulaGraph的特色。
例如无锁CAS操作需要之前的WAL全部提交后才能执行,如果一个批量写入的WAL里包含了CAS类型的WAL,就需要拆分成粒度更小的几个组,还要保证这几组WAL串行提交。
learner角色Graph
learner角色的存在主要是为了应对扩容,扩容时新增的机器需要很长时间去同步数据,如果以follower角色同步数据,会导致整个集群的高可用性下降。
新增learner角色后,会写入command类型的WAL,leader在写WAL时如果发现有add learner的command,会将learner加入自己的peers,并将它标记为learner,在统计多数派的时候,不会算上learner,但是日志还是会照常发送给它们,learner本身也不会主动发起选举。
leader切换(Transfer Leadership)Graph
leader切换对于负载均衡至关重要,当把某个分片从一台机器迁移到另一台机器时,首先会检查分片是不是leader,如果是的话,需要先切换leader,数据迁移完毕之后,通常还要重新Graph。
对于leader来说,提交leader切换命令时,就会放弃自己的leader身份,当follower收到leader切换命令时,就会发起选举。
成员变更Graph
为了避免脑裂,当一个Raft group的成员发生变化时,需要有一个中间状态,该状态下新旧group的多数派需要有重叠的部分,这样就防止了新的group或旧的group单方面做出决定。为了更加简化,Diego Ongaro在自己的博士论文中提出每次只增减一个peer的方式,以保证新旧group的多数派总是有重叠。NebulaGraph也采用了这个方式,只不过增加成员和移除成员的实现有所区别。具体实现方式请参见Raft Part class里addPeer/removePeer的实现。
listenerGraph
Raft listener进程可以从Storage服务获取数据,然后将它们写入Elasticsearch集群,以便实现全文搜索。详情请参见Graph。
与HDFS的区别Graph
Storage服务基于Raft协议实现的分布式架构,与HDFS的分布式架构有一些区别。例如:
- Storage服务本身通过Raft协议保证一致性,所有副本必须为奇数,方便进行选举leader,而HDFS存储具体数据的Datanode需要通过Namenode保证一致性,对副本数量没有要求。
- Storage服务只有leader副本提供读写服务,而HDFS的所有副本都可以提供读写服务。
- Storage服务暂时无法修改副本数量,只能在创建图空间时指定副本数量,而HDFS可以调整副本数量。
- Storage服务是直接访问文件系统,而HDFS的上层(例如HBase)需要先访问HDFS,再访问到文件系统,远程过程调用(RPC)次数更多。
总而言之,Storage服务更加轻量级,精简了一些功能,架构没有HDFS复杂,可以有效提高小文件的读写性能。