Storage 服务Graph
NebulaGraph 的存储包含两个部分,一个是 Meta 相关的存储,称为 Meta 服务,在前文已有介绍。
另一个是具体数据相关的存储,称为 Storage 服务。其运行在 nebula-storaged 进程中。本文仅介绍 Storage 服务的架构设计。
优势Graph
- 高性能(自研 KVStore)
- 易水平扩展(Shared-nothing 架构,不依赖 NAS 等硬件设备)
- 强一致性(Raft)
- 高可用性(Raft)
- 支持向第三方系统进行同步(例如Graph)
Storage 服务架构Graph
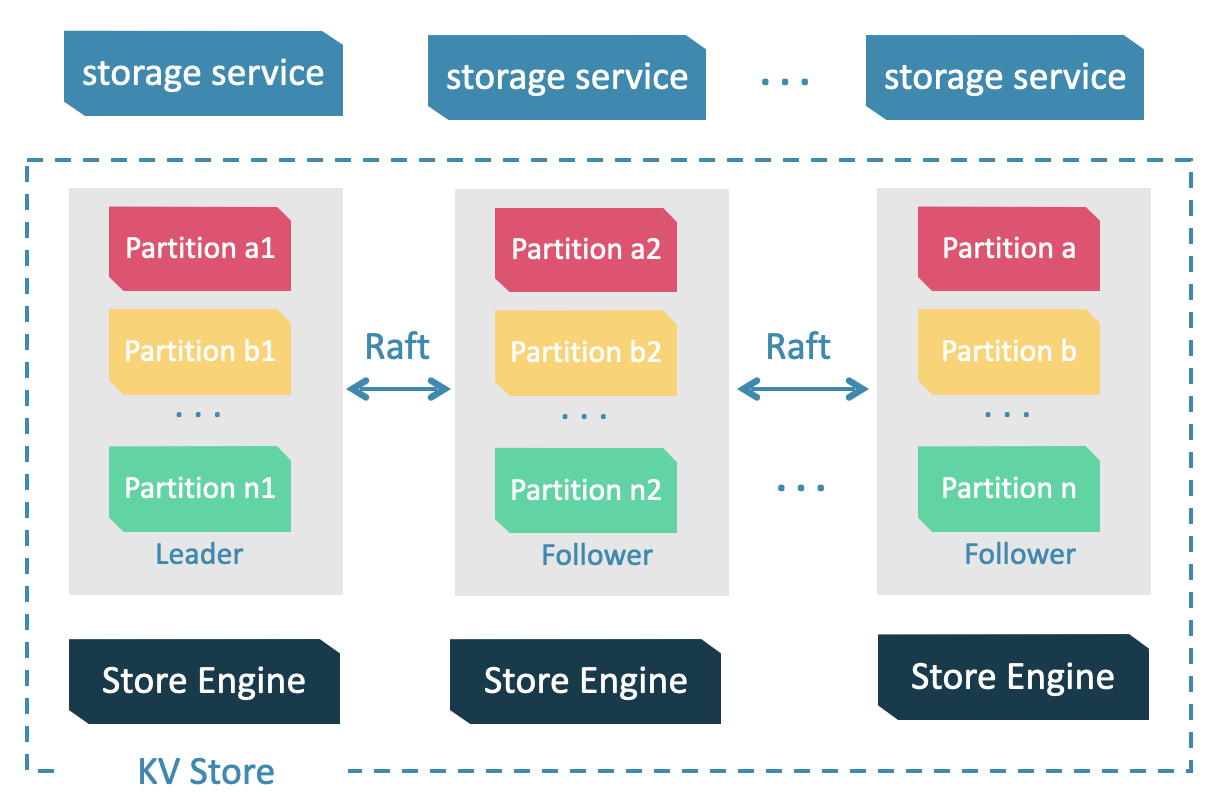
Storage 服务是由 nebula-storaged 进程提供的,用户可以根据场景配置 nebula-storaged 进程数量,例如测试环境 1 个,生产环境 3 个。
所有 nebula-storaged 进程构成了基于 Raft 协议的集群,整个服务架构可以分为三层,从上到下依次为:
-
Storage interface 层
Storage 服务的最上层,定义了一系列和图相关的 API。API 请求会在这一层被翻译成一组针对Graph的 KV 操作,例如:
getNeighbors:查询一批点的出边或者入边,返回边以及对应的属性,并且支持条件过滤。
insert vertex/edge:插入一条点或者边及其属性。
getProps:获取一个点或者一条边的属性。
正是这一层的存在,使得 Storage 服务变成了真正的图存储,否则 Storage 服务只是一个 KV 存储服务。
-
Consensus 层
Storage 服务的中间层,实现了 Graph,保证强一致性和高可用性。
-
Store Engine 层
Storage 服务的最底层,是一个单机版本地存储引擎,提供对本地数据的
get、put、scan等操作。相关接口存储在KVStore.h和KVEngine.h文件,用户可以根据业务需求定制开发相关的本地存储插件。
下文将基于架构介绍 Storage 服务的部分特性。
KVStoreGraph
NebulaGraph 使用自行开发的 KVStore,而不是其他开源 KVStore,原因如下:
- 需要高性能 KVStore。
- 需要以库的形式提供,实现高效计算下推。对于强 Schema 的 NebulaGraph 来说,计算下推时如何提供 Schema 信息,是高效的关键。
- 需要数据强一致性。
基于上述原因,NebulaGraph 使用 RocksDB 作为本地存储引擎,实现了自己的 KVStore,有如下优势:
- 对于多硬盘机器,NebulaGraph 只需配置多个不同的数据目录即可充分利用多硬盘的并发能力。
-
由 Meta 服务统一管理所有 Storage 服务,可以根据所有分片的分布情况和状态,手动进行负载均衡。
Note
不支持自动负载均衡是为了防止自动数据搬迁影响线上业务。
- 定制预写日志(WAL),每个分片都有自己的 WAL。
- 支持多个图空间,不同图空间相互隔离,每个图空间可以设置自己的分片数和副本数。
数据存储格式Graph
图存储的主要数据是点和边,NebulaGraph 将点和边的信息存储为 key,同时将点和边的属性信息存储在 value 中,以便更高效地使用属性过滤。
由于 NebulaGraph 2.0 的数据存储格式在 1.x 的基础上做了修改,下文将在介绍数据存储格式时同时介绍不同版本的差异。
- 点数据存储格式

字段 说明 Typekey 类型。长度为 1 个字节。 PartID数据分片编号。长度为 3 个字节。此字段主要用于 Storage 负载均衡(balance)时方便根据前缀扫描整个分片的数据。 VertexID点 ID。当点 ID 类型为 int 时,长度为 8 个字节;当点 ID 类型为 string 时,长度为创建图空间时指定的 fixed_string长度。TagID点关联的 Tag ID。长度为 4 个字节。
- 边数据存储格式

字段 说明 Typekey 类型。长度为 1 个字节。 PartID数据分片编号。长度为 3 个字节。此字段主要用于 Storage 负载均衡(balance)时方便根据前缀扫描整个分片的数据。 VertexID点 ID。前一个 VertexID在出边里表示起始点 ID,在"入边"里表示目的点 ID;后一个VertexID"出边"里表示目的点 ID,在"入边"里表示起始点 ID。Edge type边的类型。大于 0 表示"出边",小于 0 表示"入边"。长度为 4 个字节。 Rank用来处理两点之间有多个同类型边的情况。用户可以根据自己的需求进行设置,例如存放交易时间、交易流水号等。长度为 8 个字节, PlaceHolder预留。长度为 1 个字节。
历史版本兼容性
2.0 和 1.x 的差异如下:
- 1.x 中,点和边的
Type值相同,而在 2.0 中进行了区分,即在物理上分离了点和边,方便快速查询某个点的所有 Tag。 - 1.x 中,
VertexID仅支持 int 类型,而在 2.0 中新增了 string 类型。 - 2.0 中取消了 1.x 中的保留字段
Timestamp。 - 2.0 中边数据新增字段
PlaceHolder。 - 2.0 中修改了索引的格式,以便支持范围查询。
属性说明Graph
NebulaGraph 使用强类型 Schema。
对于点或边的属性信息,NebulaGraph 会将属性信息编码后按顺序存储。由于属性的长度是固定的,查询时可以根据偏移量快速查询。在解码之前,需要先从 Meta 服务中查询具体的 Schema 信息(并缓存)。同时为了支持在线变更 Schema,在编码属性时,会加入对应的 Schema 版本信息。
数据分片Graph
由于超大规模关系网络的节点数量高达百亿到千亿,而边的数量更会高达万亿,即使仅存储点和边两者也远大于一般服务器的容量。因此需要有方法将图元素切割,并存储在不同逻辑分片(Partition)上。NebulaGraph 采用边分割的方式。
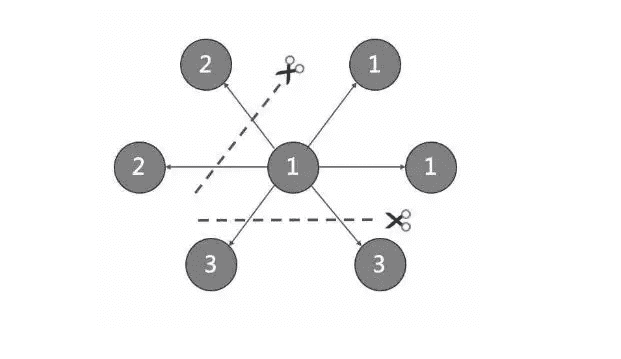
切边与存储放大Graph
NebulaGraph 中逻辑上的一条边对应着硬盘上的两个键值对(key-value pair),在边的数量和属性较多时,存储放大现象较明显。边的存储方式如下图所示。
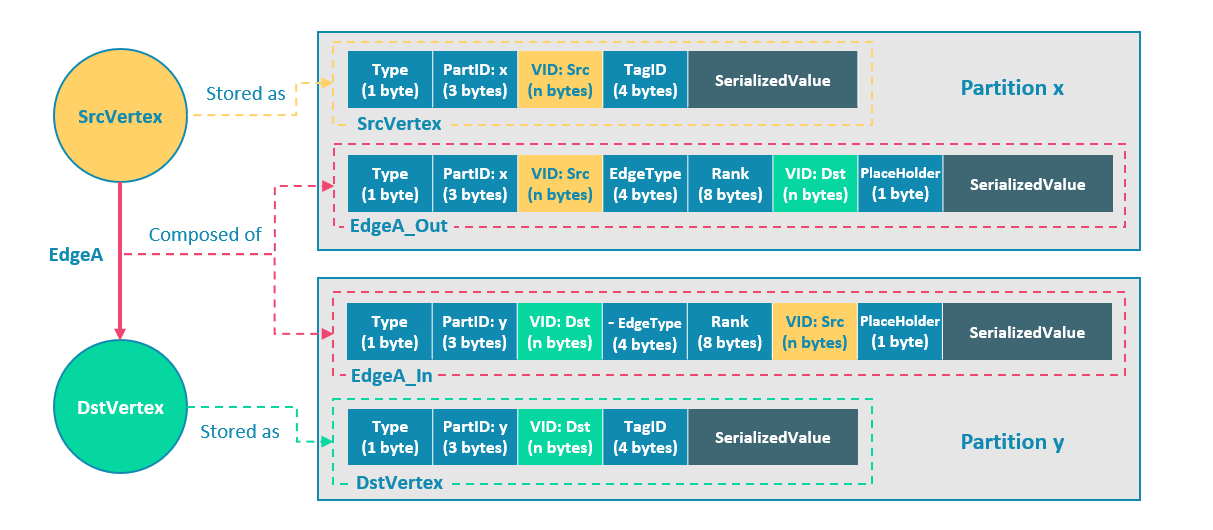
上图以最简单的两个点和一条边为例,起点 SrcVertex 通过边 EdgeA 连接目的点 DstVertex,形成路径(SrcVertex)-[EdgeA]->(DstVertex)。这两个点和一条边会以 4 个键值对的形式保存在存储层的两个不同分片,即 Partition x 和 Partition y 中,详细说明如下:
- 点 SrcVertex 的键值保存在 Partition x 中。Key 的字段有 Type、PartID(x),VID(Src)和 TagID。SerializedValue 即 Value,是序列化的点属性。
- 点 EdgeA 的第一份键值,这里用 EdgeA_Out 表示,与 SrcVertex 一同保存在 Partition x 中。Key 的字段有 Type、PartID(x)、VID(Src,即点 SrcVertex 的 ID)、EdgeType(符号为正,代表边方向为出)、Rank(0)、VID(Dst,即点 DstVertex 的 ID)和 PlaceHolder。SerializedValue 即 Value,是序列化的边属性。
- 点 DstVertex 的键值保存在 Partition y 中。Key 的字段有 Type、PartID(y),VID(Dst)和 TagID。SerializedValue 即 Value,是序列化的点属性。
- 点 EdgeA 的第二份键值,这里用 EdgeA_In 表示,与 DstVertex 一同保存在 Partition y 中。Key 的字段有 Type、PartID(y)、VID(Dst,即点 DstVertex 的 ID)、EdgeType(符号为负,代表边方向为入)、Rank(0)、VID(Src,即点 SrcVertex 的 ID)和 PlaceHolder。SerializedValue 即 Value,是序列化的边属性,与 EdgeA_Out 中该部分的完全相同。
EdgeA_Out 和 EdgeA_In 以方向相反的两条边的形式存在于存储层,二者组合成了逻辑上的一条边 EdgeA。EdgeA_Out 用于从起点开始的遍历请求,例如(a)-[]->();EdgeA_In 用于指向目的点的遍历请求,或者说从目的点开始,沿着边的方向逆序进行的遍历请求,例如例如()-[]->(a)。
如 EdgeA_Out 和 EdgeA_In 一样,NebulaGraph 冗余了存储每条边的信息,导致存储边所需的实际空间翻倍。因为边对应的 Key 占用的硬盘空间较小,但 Value 占用的空间与属性值的长度和数量成正比,所以,当边的属性值较大或数量较多时候,硬盘空间占用量会比较大。
如果对边进行操作,为了保证两个键值对的最终一致性,可以开启 Graph,开启后,会先在正向边所在的分片进行操作,然后在反向边所在分片进行操作,最后返回结果。
分片算法Graph
分片策略采用静态 Hash 的方式,即对点 VID 进行取模操作,同一个点的所有 Tag、出边和入边信息都会存储到同一个分片,这种方式极大地提升了查询效率。
Note
创建图空间时需指定分片数量,分片数量设置后无法修改,建议设置时提前满足业务将来的扩容需求。
点和边分布在不同的分片,分片分布在不同的机器。分片数量在 CREATE SPACE 语句中指定,此后不可更改。
如果需要将某些点放置在相同的分片(例如在一台机器上),可以参考Graph。
下文用简单代码说明 VID 和分片的关系。
// 如果 ID 长度为 8,为了兼容 1.0,将数据类型视为 int64。
uint64_t vid = 0;
if (id.size() == 8) {
memcpy(static_cast<void*>(&vid), id.data(), 8);
} else {
MurmurHash2 hash;
vid = hash(id.data());
}
PartitionID pId = vid % numParts + 1;
简单来说,上述代码是将一个固定的字符串进行哈希计算,转换成数据类型为 int64 的数字(int64 数字的哈希计算结果是数字本身),将数字取模,然后加 1,即:
pId = vid % numParts + 1;
示例的部分参数说明如下。
| 参数 | 说明 |
|---|---|
% |
取模运算。 |
numParts |
VID所在图空间的分片数,即 Graph 语句中的partition_num值。 |
pId |
VID所在分片的 ID。 |
例如有 100 个分片,VID为 1、101 和 1001 的三个点将会存储在相同的分片。分片 ID 和机器地址之间的映射是随机的,所以不能假定任何两个分片位于同一台机器上。
RaftGraph
关于 Raft 的简单介绍Graph
分布式系统中,同一份数据通常会有多个副本,这样即使少数副本发生故障,系统仍可正常运行。这就需要一定的技术手段来保证多个副本之间的一致性。
基本原理:Raft 就是一种用于保证多副本一致性的协议。Raft 采用多个副本之间竞选的方式,赢得”超过半数”副本投票的(候选)副本成为 Leader,由 Leader 代表所有副本对外提供服务;其他 Follower 作为备份。当该 Leader 出现异常后(通信故障、运维命令等),其余 Follower 进行新一轮选举,投票出一个新的 Leader。Leader 和 Follower 之间通过心跳的方式相互探测是否存活,并以 Raft-wal 的方式写入硬盘,超过多个心跳仍无响应的副本会认为发生故障。
Note
因为 Raft-wal 需要定期写硬盘,如果硬盘写能力瓶颈会导致 Raft 心跳失败,导致重新发起选举。硬盘 IO 严重堵塞情况下,会导致长期无法选举出 Leader。
读写流程:对于客户端的每个写入请求,Leader 会将该写入以 Raft-wal 的方式,将该条同步给其他 Follower,并只有在“超过半数”副本都成功收到 Raft-wal 后,才会返回客户端该写入成功。对于客户端的每个读取请求,都直接访问 Leader,而 Follower 并不参与读请求服务。
故障流程:场景 1:考虑一个配置为单副本(图空间)的集群;如果系统只有一个副本时,其自身就是 Leader;如果其发生故障,系统将完全不可用。场景 2:考虑一个配置为 3 副本(图空间)的集群;如果系统有 3 个副本,其中一个副本是 Leader,其他 2 个副本是 Follower;即使原 Leader 发生故障,剩下两个副本仍可投票出一个新的 Leader(以及一个 Follower),此时系统仍可使用;但是当这 2 个副本中任一者再次发生故障后,由于投票人数不足,系统将完全不可用。
Note
Raft 多副本的方式与 HDFS 多副本的方式是不同的,Raft 基于“多数派”投票,因此副本数量不能是偶数。
Multi Group RaftGraph
由于 Storage 服务需要支持集群分布式架构,所以基于 Raft 协议实现了 Multi Group Raft,即每个分片的所有副本共同组成一个 Raft group,其中一个副本是 leader,其他副本是 follower,从而实现强一致性和高可用性。Raft 的部分实现如下。
由于 Raft 日志不允许空洞,NebulaGraph 使用 Multi Group Raft 缓解此问题,分片数量较多时,可以有效提高 NebulaGraph 的性能。但是分片数量太多会增加开销,例如 Raft group 内部存储的状态信息、WAL 文件,或者负载过低时的批量操作。
实现 Multi Group Raft 有 2 个关键点:
-
共享 Transport 层
每一个 Raft group 内部都需要向对应的 peer 发送消息,如果不能共享 Transport 层,会导致连接的开销巨大。
-
共享线程池
如果不共享一组线程池,会造成系统的线程数过多,导致大量的上下文切换开销。
批量(Batch)操作Graph
NebulaGraph 中,每个分片都是串行写日志,为了提高吞吐,写日志时需要做批量操作,但是由于 NebulaGraph 利用 WAL 实现一些特殊功能,需要对批量操作进行分组,这是 NebulaGraph 的特色。
例如无锁 CAS 操作需要之前的 WAL 全部提交后才能执行,如果一个批量写入的 WAL 里包含了 CAS 类型的 WAL,就需要拆分成粒度更小的几个组,还要保证这几组 WAL 串行提交。
leader 切换(Transfer Leadership)Graph
leader 切换对于负载均衡至关重要,当把某个分片从一台机器迁移到另一台机器时,首先会检查分片是不是 leader,如果是的话,需要先切换 leader,数据迁移完毕之后,通常还要重新Graph。
对于 leader 来说,提交 leader 切换命令时,就会放弃自己的 leader 身份,当 follower 收到 leader 切换命令时,就会发起选举。
成员变更Graph
为了避免脑裂,当一个 Raft group 的成员发生变化时,需要有一个中间状态,该状态下新旧 group 的多数派需要有重叠的部分,这样就防止了新的 group 或旧的 group 单方面做出决定。为了更加简化,Diego Ongaro 在自己的博士论文中提出每次只增减一个 peer 的方式,以保证新旧 group 的多数派总是有重叠。NebulaGraph 也采用了这个方式,只不过增加成员和移除成员的实现有所区别。具体实现方式请参见 Raft Part class 里 addPeer/removePeer 的实现。
与 HDFS 的区别Graph
Storage 服务基于 Raft 协议实现的分布式架构,与 HDFS 的分布式架构有一些区别。例如:
- Storage 服务本身通过 Raft 协议保证一致性,副本数量通常为奇数,方便进行选举 leader,而 HDFS 存储具体数据的 DataNode 需要通过 NameNode 保证一致性,对副本数量没有要求。
- Storage 服务只有 leader 副本提供读写服务,而 HDFS 的所有副本都可以提供读写服务。
- Storage 服务无法修改副本数量,只能在创建图空间时指定副本数量,而 HDFS 可以调整副本数量。
- Storage 服务是直接访问文件系统,而 HDFS 的上层(例如 HBase)需要先访问 HDFS,再访问到文件系统,远程过程调用(RPC)次数更多。
总而言之,Storage 服务更加轻量级,精简了一些功能,架构没有 HDFS 复杂,可以有效提高小块存储的读写性能。
视频Graph
用户也可以通过视频全方位了解 NebulaGraph 的存储设计。
- Graph(24 分 29 秒)