常见问题 FAQ¶
本文列出了使用 Nebula Graph 3.1.0 时可能遇到的常见问题,用户可以使用文档中心或者浏览器的搜索功能查找相应问题。
如果按照文中的建议无法解决问题,请到 Nebula Graph 论坛 提问或提交 GitHub issue。
关于本手册¶
为什么手册示例和系统行为不一致?¶
Nebula Graph 一直在持续开发,功能或操作的行为可能会有变化,如果发现不一致,请提交 issue 通知 Nebula Graph 团队。
Note
如果发现本文档中的错误:
- 用户可以点击页面顶部右上角的"铅笔"图标进入编辑页面。
- 使用 Markdown 修改文档。完成后点击页面底部的 "Commit changes",这会触发一个 GitHub pull request。
- 完成 CLA 签署,并且至少 2 位 reviewer 审核通过即可合并。
关于历史兼容性¶
X版本兼容性
Nebula Graph 3.1.0 与 历史版本 (包括 Nebula Graph 1.x 和 2.x) 的数据格式、客户端通信协议均双向不兼容。 使用老版本客户端连接新版本服务端,会导致服务进程退出。 数据格式升级参见升级 Nebula Graph 历史版本至当前版本。 客户端与工具均需要下载对应版本。
关于执行报错¶
如何处理错误信息 SemanticError: Missing yield clause.¶
从 Nebula Graph 3.0.0 开始,查询语句LOOKUP、GO、FETCH必须用YIELD子句指定输出结果。详情请参见YIELD。
如何处理错误信息 Host not enough!¶
从 3.0.0 版本开始,在配置文件中添加的 Storage 节点无法直接读写,配置文件的作用仅仅是将 Storage 节点注册至 Meta 服务中。必须使用ADD HOSTS命令后,才能正常读写 Storage 节点。详情参见管理 Storage 主机。
如何处理错误信息 To get the property of the vertex in 'v.age', should use the format 'var.tag.prop'¶
从 3.0.0 版本开始,pattern支持同时匹配多个 Tag,所以返回属性时,需要额外指定 Tag 名称。即从RETURN 变量名.属性名改为RETURN 变量名.Tag名.属性名。
如何处理错误信息 Storage Error E_RPC_FAILURE¶
报错原因通常为 Graph 服务向 Storage 服务请求了过多的数据,导致 Storage 服务超时。请尝试以下解决方案:
- 修改配置文件:在
nebula-graphd.conf文件中修改--storage_client_timeout_ms参数的值,以增加 Storage client 的连接超时时间。该值的单位为毫秒(ms)。例如,设置--storage_client_timeout_ms=60000。如果nebula-graphd.conf文件中未配置该参数,请手动增加。提示:请在配置文件开头添加--local_config=true 再重启服务。 - 优化查询语句:减少全库扫描型的查询,无论是否用
LIMIT限制了返回结果的数量;用 GO 语句改写 MATCH 语句(前者有优化,后者无优化)。 - 检查 Storaged 是否发生过 OOM。(
dmesg |grep nebula)。 - 为 Storage 服务器提供性能更好的 SSD 或者内存。
- 重试请求。
如何处理错误信息 The leader has changed. Try again later¶
已知问题,通常需要重试 1-N 次 (N==partition 数量)。原因为 meta client 更新 leader 缓存需要 1-2 个心跳或者通过错误触发强制更新。
编译 Exchange、Connectors、Algorithm 时无法下载 SNAPSHOT 包¶
现象:编译时提示Could not find artifact com.vesoft:client:jar:xxx-SNAPSHOT。
原因:本地 maven 没有配置用于下载 SNAPSHOT 的仓库。maven 中默认的 central 仓库用于存放正式发布版本,而不是开发版本(SNAPSHOT)。
解决方案:在 maven 的 setting.xml文件的profiles作用域内中增加以下配置:
<profile>
<activation>
<activeByDefault>true</activeByDefault>
</activation>
<repositories>
<repository>
<id>snapshots</id>
<url>https://oss.sonatype.org/content/repositories/snapshots/</url>
<snapshots>
<enabled>true</enabled>
</snapshots>
</repository>
</repositories>
</profile>
如何处理错误信息[ERROR (-1004)]: SyntaxError: syntax error near?¶
大部分情况下,查询语句需要有YIELD或RETURN,请检查查询语句是否包含。
如何处理错误信息can’t solve the start vids from the sentence¶
查询引擎需要知道从哪些 VID 开始图遍历。这些开始图遍历的 VID,或者通过用户指定,例如:
> GO FROM ${vids} ...
> MATCH (src) WHERE id(src) == ${vids}
# 开始图遍历的 VID 通过如上办法指定
或者通过一个属性索引来得到,例如:
# CREATE TAG INDEX IF NOT EXISTS i_player ON player(name(20));
# REBUILD TAG INDEX i_player;
> LOOKUP ON player WHERE player.name == "abc" | ... YIELD ...
> MATCH (src) WHERE src.name == "abc" ...
# 通过点属性 name 的索引,来得到 VID
否则,就会抛出这样一个异常 can’t solve the start vids from the sentence。
如何处理错误信息Wrong vertex id type: 1001¶
检查输入的 VID 类型是否是create space设置的INT64或FIXED_STRING(N)。详情请参见 create space。
如何处理错误信息The VID must be a 64-bit integer or a string fitting space vertex id length limit.¶
检查输入的 VID 是否超过限制长度。详情请参见 create space。
如何处理错误信息 edge conflict 或 vertex conflict¶
Storage 服务在毫秒级时间内多次收到插入或者更新同一点或边的请求时,可能返回该错误。请稍后重试。
如何处理错误信息 RPC failure in MetaClient: Connection refused¶
报错原因通常为 metad 服务状态异常,或是 metad 和 graphd 服务所在机器网络不通。请尝试以下解决方案:
- 在 metad 所在服务器查看下 metad 服务状态,如果服务状态异常,可以重新启动 metad 服务。
- 在报错服务器下使用
telnet meta-ip:port查看网络状态。
- 检查配置文件中的端口配置,如果端口号与连接时使用的不同,改用配置文件中的端口或者修改配置。
如何处理 nebula-graph.INFO 中错误日志 StorageClientBase.inl:214] Request to "x.x.x.x":9779 failed: N6apache6thrift9transport19TTransportExceptionE: Timed Out¶
报错原因可能是查询的数据量比较大,storaged 处理超时。请尝试以下解决方法:
- 导入数据时,手动 compaction,加速读的速度。
- 增加 Graph 服务与 Storage 服务的 RPC 连接超时时间,在
nebula-storaged.conf文件里面修改--storage_client_timeout_ms参数的值。该值的单位为毫秒(ms),默认值为 60000 毫秒。
如何处理 nebula-storaged.INFO 中错误日志 MetaClient.cpp:65] Heartbeat failed, status:Wrong cluster! 或者 nebula-metad.INFO 含有错误日志HBProcessor.cpp:54] Reject wrong cluster host "x.x.x.x":9771!¶
报错的原因可能是用户修改了 metad 的 ip 或者端口信息,或者 storage 之前加入过其他集群。请尝试以下解决方法:
用户到 storage 部署的机器所在的安装目录(默认安装目录为 /usr/local/nebula)下面将cluster.id文件删除,然后重启 storaged 服务。
关于设计与功能¶
返回消息中 time spent 的含义是什么?¶
将命令SHOW SPACES返回的消息作为示例:
nebula> SHOW SPACES;
+--------------------+
| Name |
+--------------------+
| "basketballplayer" |
+--------------------+
Got 1 rows (time spent 1235/1934 us)
- 第一个数字
1235表示数据库本身执行该命令花费的时间,即查询引擎从客户端接收到一个查询,然后从存储服务器获取数据并执行一系列计算所花费的时间。
- 第二个数字
1934表示从客户端角度看所花费的时间,即从客户端发送请求、接收结果,然后在屏幕上显示结果所花费的时间。
为什么在正常连接 Nebula Graph 后,nebula-storaged进程的端口号一直显示红色?¶
nebula-storaged进程的端口号的红色闪烁状态是因为nebula-storaged在启动流程中会等待nebula-metad添加当前 Storage 服务,当前 Storage 服务收到 Ready 信号后才会正式启动服务。从 3.0.0 版本开始,Meta 服务无法直接读写在配置文件中添加的 Storage 服务,配置文件的作用仅仅是将 Storage 服务注册至 Meta 服务中。用户必须使用ADD HOSTS命令后,才能使 Meta 服务正常读写 Storage 服务。更多信息,参见管理 Storage 主机。
为什么 Nebula Graph 的返回结果每行之间没有横线分隔了?¶
这是 Nebula Console 2.6.0 版本的变动造成的,不是 Nebula Graph 内核的变更,不影响返回数据本身的内容。
关于悬挂边¶
悬挂边 (Dangling edge) 是指一条边的起点或者终点在数据库中不存在。
Nebula Graph 3.1.0 的数据模型中,由于设计允许图中存在“悬挂边”; 没有 openCypher 中的 MERGE 语句。 对于悬挂边的保证完全依赖应用层面。 详见 INSERT VERTEX, DELETE VERTEX, INSERT EDGE, DELETE EDGE。
可以在CREATE SPACE时设置replica_factor为偶数(例如设置为 2)吗?¶
不要这样设置。
Storage 服务使用 Raft 协议(多数表决),为保证可用性,要求出故障的副本数量不能达到一半。
当机器数量为 1 时,replica_factor只能设置为1。
当机器数量足够时,如果replica_factor=2,当其中一个副本故障时,就会导致系统无法正常工作;如果replica_factor=4,只能有一个副本可以出现故障,这和replica_factor=3是一样。以此类推,所以replica_factor设置为奇数即可。
建议在生产环境中设置replica_factor=3,测试环境中设置replica_factor=1,不要使用偶数。
是否支持停止或者中断慢查询¶
支持。
详情请参见终止查询。
使用GO和MATCH执行相同语义的查询,查询结果为什么不同?¶
原因可能有以下几种:
GO查询到了悬挂边。
RETURN命令未指定排序方式。
- 触发了 Storage 服务中
max_edge_returned_per_vertex定义的稠密点截断限制。
-
路径的类型不同,导致查询结果可能会不同。
GO语句采用的是walk类型,遍历时点和边可以重复。
MATCH语句兼容 openCypher,采用的是trail类型,遍历时只有点可以重复,边不可以重复。
因路径类型不同导致查询结果不同的示例图和说明如下。
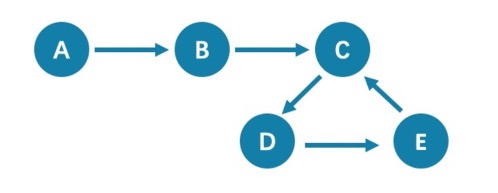
从点 A 开始查询距离 5 跳的点,都会查询到点 C(A->B->C->D->E->C),查询 6 跳的点时,GO语句会查询到点 D(A->B->C->D->E->C->D),因为边C->D可以重复查询,而MATCH语句查询为空,因为边不可以重复。
所以使用GO和MATCH执行相同语义的查询,可能会出现MATCH语句的查询结果比GO语句少。
关于路径的详细说明,请参见维基百科。
如何统计每种 Tag 有多少个点,每个 Edge type 有多少条边?¶
请参见 show-stats。
如何获取每种 Tag 的所有点,或者每种 Edge type 的所有边?¶
-
建立并重建索引。
> CREATE TAG INDEX IF NOT EXISTS i_player ON player(); > REBUILD TAG INDEX i_player; -
使用
LOOKUP或MATCH语句。例如:> LOOKUP ON player; > MATCH (n:player) RETURN n;
如何在不指定 Tag/EdgeType 的情况下,获取所有的点和边?¶
nGQL 没有该功能。
你必须先指定 Tag/EdgeType,或者用LIMIT子句限制返回数量,才能获取对应类型的所有的点和边。
例如执行 MATCH (n) RETURN (n). 会返回错误 Scan vertices or edges need to specify a limit number, or limit number can not push down.。
一个办法是使用 Nebula Algorithm.
或者指定各 Tag/Edge Type,然后再自己通过 Union 拼装。
能不能用中文字符做标识符,比如图空间、Tag、Edge type、属性、索引的名称?¶
能,详情参见关键字和保留字。
获取指定点的出度(或者入度)?¶
一个点的“出度”是指从该点出发的“边”的条数。入度,是指指向该点的边的条数。
nebula > MATCH (s)-[e]->() WHERE id(s) == "given" RETURN count(e); #出度
nebula > MATCH (s)<-[e]-() WHERE id(s) == "given" RETURN count(e); #入度
因为没有对出度和入度的进行特殊处理(例如索引或者缓存),这是一个较慢的操作。特别当遇到超级节点时,可能会发生OOM。
是否有办法快速获取“所有”点的出度和入度?¶
没有直接命令。
可以使用 Nebula Algorithm。
关于运维¶
运行日志文件过大时如何回收日志?¶
Nebula Graph 的运行日志默认在 /usr/local/nebula/logs/ 下,正常 INFO 级别日志文件为 nebula-graphd.INFO, nebula-storaged.INFO, nebula-metad.INFO,报警和错误级别后缀为 .WARNING 和 .ERROR。
Nebula Graph 使用 glog 打印日志。glog 没有日志回收的功能,用户可以:
- 使用 crontab 设置定期任务回收日志文件,详情请参见 Glog should delete old log files automatically。
- 使用 logrotate 实现日志轮询。使用 logrotate 管理日志前需修改相应 Nebula Graph 服务的配置,将
timestamp_in_logfile_name参数的值改成false。
如何查看 Nebula Graph 版本¶
服务运行时:nebula-console 中执行命令 SHOW HOSTS META,详见 SHOW HOSTS
服务未运行时:在安装路径的bin目录内,执行./<binary_name> --version命令,可以查看到 version 和 GitHub 上的 commit ID,例如:
$ ./nebula-graphd --version
-
Docker Compose 部署
查看 Docker Compose 部署的 Nebula Graph 版本,方式和编译安装类似,只是要先进入容器内部,示例命令如下:
docker exec -it nebula-docker-compose_graphd_1 bash cd bin/ ./nebula-graphd --version
-
RPM/DEB 包安装
执行
rpm -qa |grep nebula即可查看版本。
如何扩缩容(仅限企业版)¶
- 使用 Dashboard(企业版),在可视化页面对 graphd 和 storaged 进行快速扩缩容,详情参见集群操作-扩缩容。
- 使用 Nebula Operator 扩缩容集群,详情参见使用 Kubectl 部署 Nebula Graph 集群和使用 Helm 部署 Nebula Graph 集群。
Nebula Graph 3.1.0 未提供运维命令以实现自动扩缩容,参考以下步骤:
-
metad 的扩容和缩容: metad 不支持自动扩缩容。
Note
用户可以使用脚本工具 迁移 meta 服务,但是需要自行修改 Graph 服务和 Storage 服务的配置文件中的 Meta 设置。
- graphd 的缩容:将该 graphd 的 ip 从 client 的代码中移除,关闭该 graphd 进程。
- graphd 的扩容:在新机器上准备 graphd 二进制文件和配置文件,在配置文件中修改或增加已在运行的 metad 地址,启动 graphd 进程。
- storaged 的缩容:详情参见缩容命令。完成后关闭 storaged 进程。
-
storaged 的扩容:在新机器上准备 storaged 二进制文件和配置文件,在配置文件中修改或增加已在运行的 metad 地址,然后注册 storaged 到 metad 并启动 storaged 进程。详情参见注册 Storage 服务。
storaged 扩缩容之后,还需要运行 Balance Data 和 Balance Leader 命令。
修改 Host 名称后,旧的 Host 一直显示 OFFLINE 怎么办?¶
OFFLINE 状态的 Host 将在一天后自动删除。
关于连接¶
防火墙中需要开放哪些端口?¶
如果没有修改过配置文件 中预设的端口,请在防火墙中开放如下端口:
| 服务类型 | 端口 |
|---|---|
| Meta | 9559, 9560, 19559, 19560 |
| Graph | 9669, 19669, 19670 |
| Storage | 9777 ~ 9780, 19779, 19780 |
如果修改过配置文件中预设的端口,请找出实际使用的端口并在防火墙中开放它们。
周边工具各自使用不用的端口,请参考各工具文档。
如何测试端口是否已开放?¶
用户可以使用如下 telnet 命令检查端口状态:
telnet <ip> <port>
Note
如果无法使用 telnet 命令,请先检查主机中是否安装并启动了 telnet。
示例:
// 如果端口已开放:
$ telnet 192.168.1.10 9669
Trying 192.168.1.10...
Connected to 192.168.1.10.
Escape character is '^]'.
// 如果端口未开放:
$ telnet 192.168.1.10 9777
Trying 192.168.1.10...
telnet: connect to address 192.168.1.10: Connection refused
关于 License¶
Dashboard/Explorer/Nebula Graph 企业版的 License 一样吗?¶
不一样,Dashboard、Explorer、Nebula Graph 企业版的 License 相互独立,不可互用。
在 Nebula Graph 企业版的 License 使用有效期期间,将企业版 Meta 替换成社区版 Meta 后,可以和企业版的 Graph、Storage一起使用吗?¶
不可以,不支持企业版和社区版的 Nebula Graph 的混合部署。
Nebula Graph 企业版的 License 到期后,是否可以将data目录的数据替换至社区版的 Nebula Graph 中使用?¶
可以。企业版和社区版的数据可以通用。只有在都是社区版部署的服务中才可以正常使用替换后的数据。不支持企业版和社区版的混合部署,例如,不支持混合部署企业版的 Meta 服务和社区版的 Graph、Storage 服务。
License 过期前,是否有信息提示?License 过期后如何续期?¶
License 过期前,系统会发送过期提醒信息。
正式版的 License 和试用版的 License 的过期前的提醒时间不同。
-
正式版的 License 过期提醒:
- 过期前 30 天和过期当天,在启动服务时有过期提醒。
- 到期后有 14 天缓冲期。在缓冲期期间,有过期提示,用户能继续使用 Nebula Graph/Dashboard/Explorer。缓冲期结束后,服务会停机并无法启动。
-
试用版的 License 过期提醒:
- 过期前 7 天和过期当天,在启动服务时有过期提醒。
- 无缓冲期。License 到期后,无法启动服务。
License 过期后,请及时联系销售(inqury@vesoft.com)更换新的证书。