集群诊断¶
集群诊断是在指定的时间范围内,定位及分析当前集群出现的问题,并将诊断结果和集群相关的监控信息生成网页版的诊断报告。
功能介绍¶
- 通过诊断报告可以排查出当前集群出现的问题,并可以对问题进行解决。
- 快速了解集群内各个节点以及服务,Session,服务配置的基本情况。
- 根据诊断的报告信息,做出运维建议和集群预警。
诊断入口¶
- 在 Dashboard 企业版顶部导航栏,单击集群管理。
- 单击目标集群右侧详情。
- 在左侧导航栏,单击集群信息->集群诊断。
创建诊断¶
-
选择诊断的时间范围。支持自定义诊断时间和通过时间区间设置集群诊断的范围,包括:
1 小时、6 小时、12 小时、1 天、3 天、7 天、14 天。Caution
集群诊断是对集群历史数据的诊断,因此用户设置的诊断范围的结束时间不能超过当前时间。
-
在集群诊断页面,单击开始诊断。
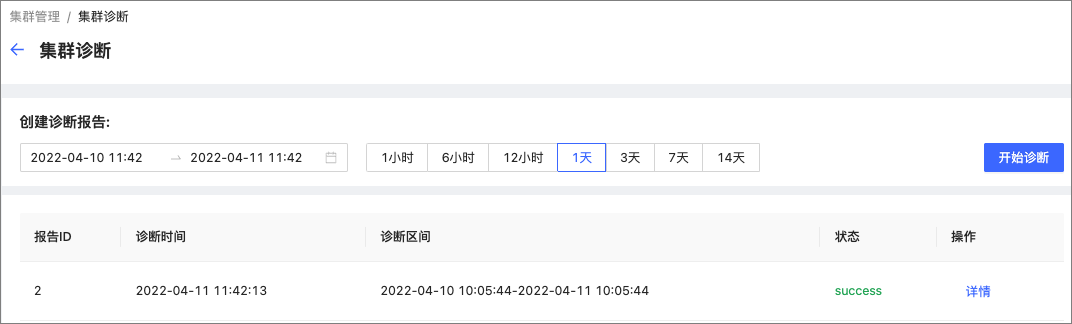
-
当诊断状态由 generating 变为 success 时,即表示诊断已经完成。
查看诊断报告¶
在诊断列表中,单击目标诊断右侧的详情。
集群诊断报告中包含以下内容:
- 诊断结果
- 基本信息
- 负载
- Network
- Session
- 服务信息
- 配置信息
诊断结果¶
-
当以下参数出现异常时,诊断结果中会显示相应的信息,包括参数名、类型、严重程度、详情。
参数 说明 num_queries_hit_memory_watermark执行的 nGQL 语句中达到内存水位值的数量。 graphd_downGraph 服务停止运行。 storaged_downStorage 服务停止运行。 metad_downMeta 服务停止运行。 node-exporter down用于收集节点系统数据的服务停止运行。
- 当未诊断到任何异常时,诊断结果中不显示诊断信息。
基本信息¶
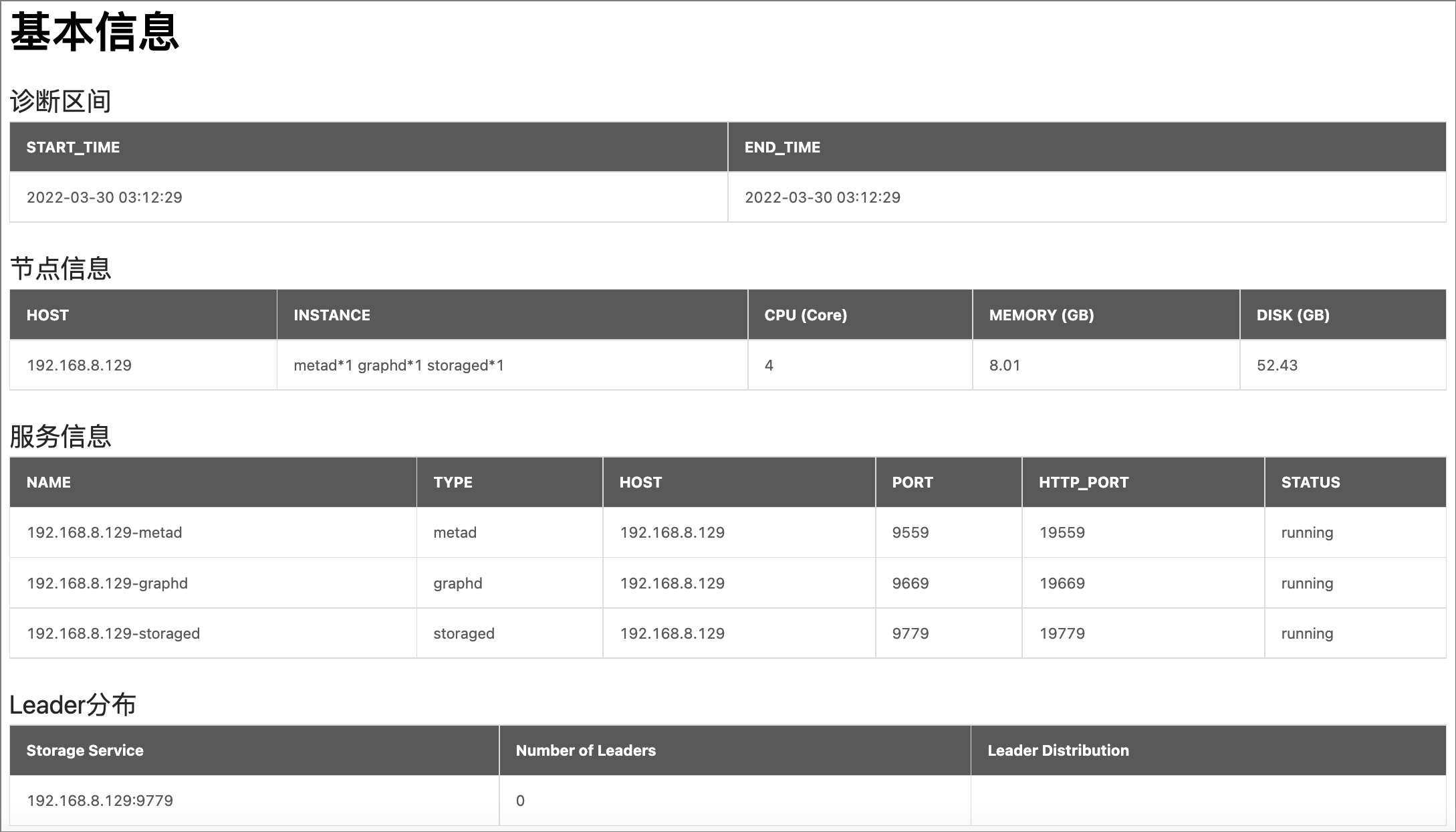
- 诊断区间:显示生成报告的时间范围,包括开始时间和结束时间。
-
节点信息:显示集群中节点的数量、CPU、内存、磁盘等信息。
参数 说明 HOST服务器的 IP 地址。 INSTANCE该服务器部署的实例数量,例如: metad*1 graphd*1 storaged*1。CPUCPU 核数,单位 Core。 MEMORY表示服务器的内存大小,单位是 GB。 DISK表示服务器磁盘大小,单位是 GB。
- 服务信息:显示 Nebula Graph 各个服务的类型、所在节点 IP、端口、HTTP 端口、运行状态。
-
Leader分布:显示 Storage 服务中 Leader 分布情况。
参数 说明 Storage Service显示 Storage 服务的访问地址。 Number of Leaders显示 Storage 服务中的 Leader 总数 。 Leader Distribution显示 Storage 服务中不同图空间的 Leader 分布数。
负载¶
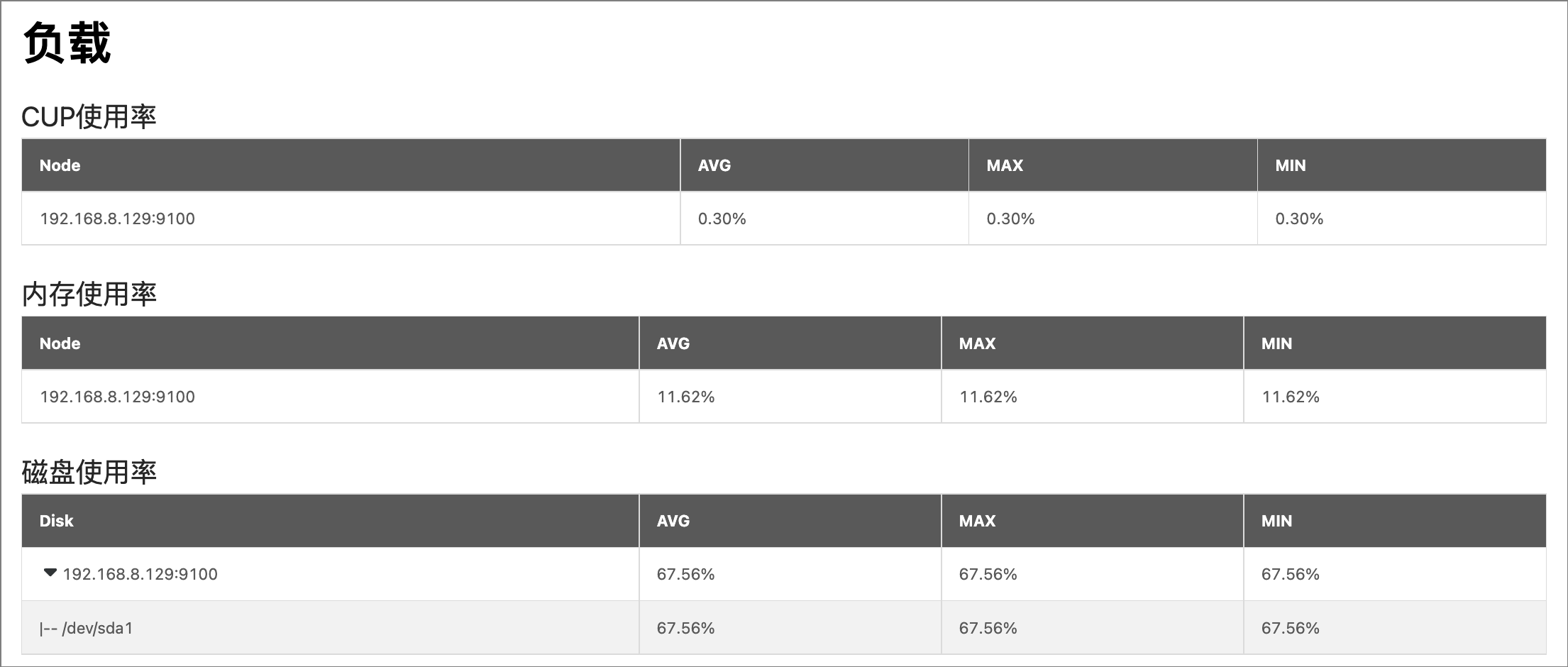
显示集群所有服务器节点的负载信息,包括以下指标的平均值(AVG)、最大值(MAX)、最小值(MIN):
- 内存使用率:显示节点内存使用率,单位是 %。
- CPU使用率:显示节点 CPU 使用率,单位是 %。
- 磁盘使用率:显示节点磁盘的总使用率,及节点中各个磁盘的使用率,单位是 %。
Network¶
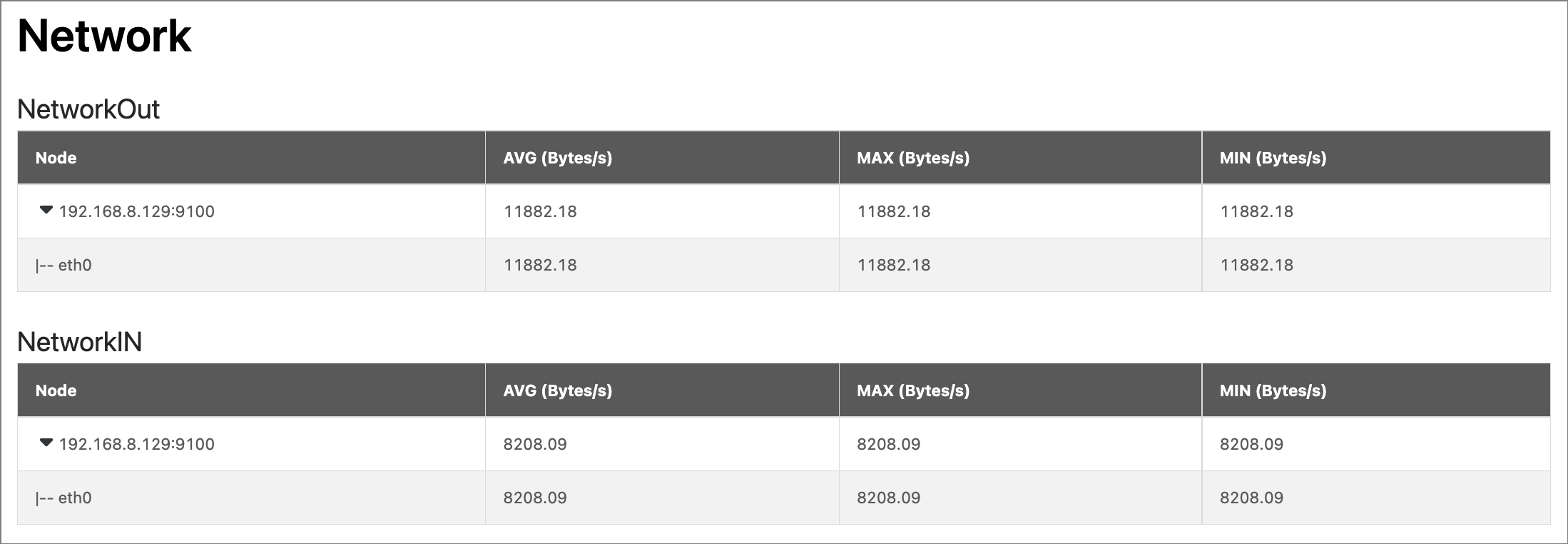
显示集群所有服务器节点的网络流量信息,包括以下指标的平均值(AVG)、最大值(MAX)、最小值(MIN):
- NetworkOut:显示集群中各个服务器节点的网络流出速度的大小,及每个节点中各网卡的流出速度大小,单位是 Bytes/s。
- NetworkIn:显示集群中各个服务器节点的网络流入速度的大小,及每个节点中各网卡的流入速度大小,单位是 Bytes/s。
Session¶

显示集群中所有 Graph 服务的 Session 相关信息。
| 参数 | 说明 |
|---|---|
num_opened_sessions |
服务端建立过的会话数量。 |
num_auth_failed_sessions |
登录验证失败的会话数量。 |
num_active_sessions |
当前活跃的会话数量。 |
num_reclaimed_expired_sessions |
服务端主动回收的过期的会话数量。 |
服务信息¶
显示集群各服务稳定性相关的指标:
-
Graph:
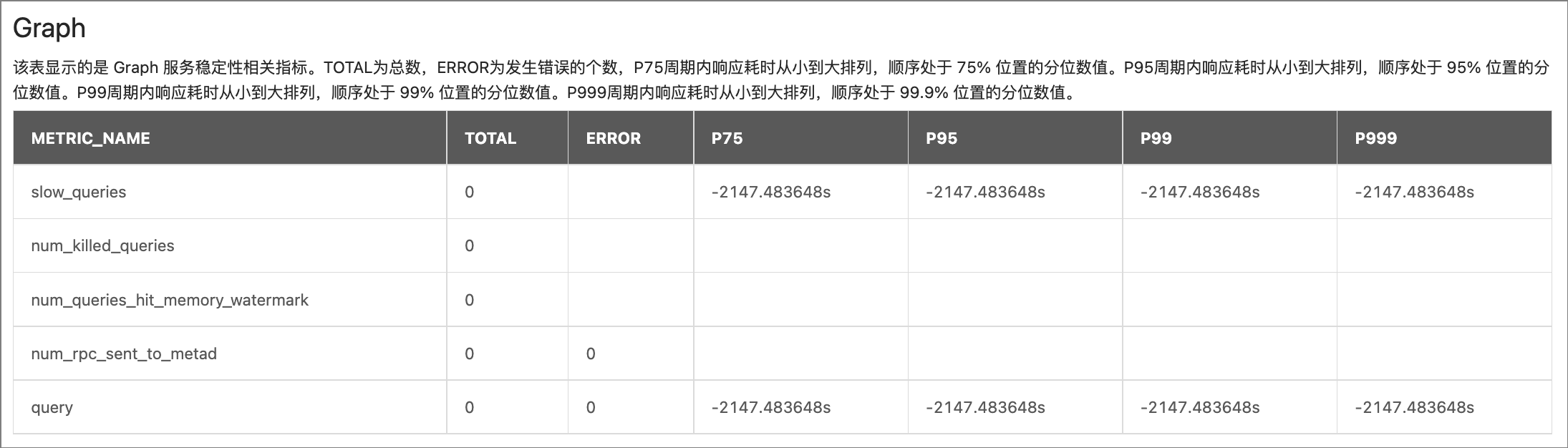
参数 说明 METRIC_NAMEquery:查询次数。
slow_queries:慢查询次数。num_killed_queries:被终止的查询数量。num_queries_hit_memory_watermark:执行的 nGQL 语句中达到内存水位值的数量。num_rpc_sent_to_metad:Graphd 服务发给 Metad 服务的 RPC 请求数量。
-
Meta:

参数 说明 METRIC_NAMEheartbeat:心跳次数。
-
Storage:
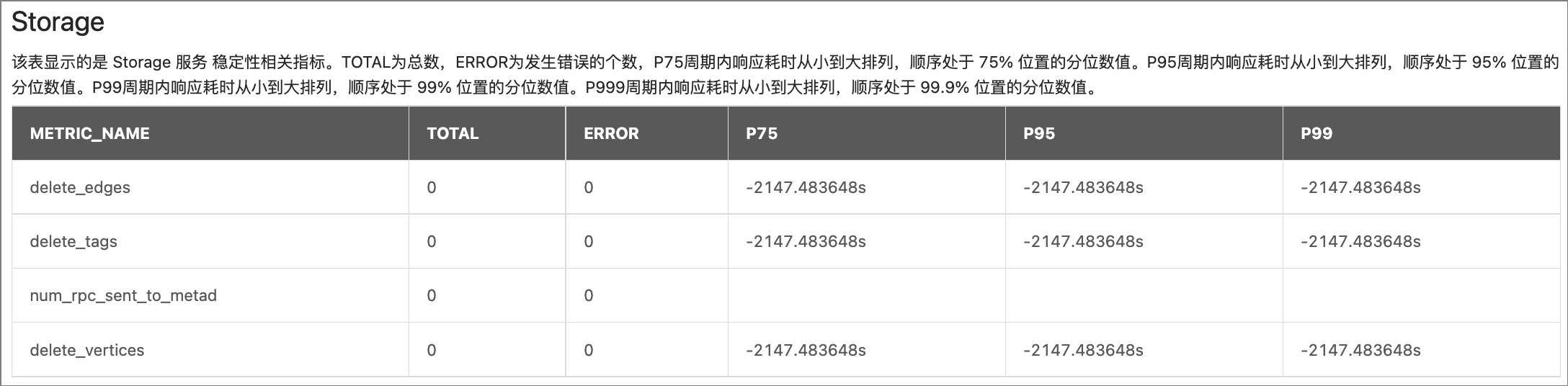
参数 说明 METRIC_NAMEdelete_vertices:删除的点的数量。
delete_edges:删除的边的数量。delete_tags:删除的 Tag 的数量。num_rpc_sent_to_metad:Storaged 服务发给 Metad 服务的 RPC 请求数量。
其他参数说明如下:
| 参数 | 说明 |
|---|---|
TOTAL |
该项监控执行的总次数。 |
ERROR |
发生错误的个数。 |
P75 |
P75 周期内响应耗时从小到大排列,顺序处于 75% 位置的分位数值。 |
P95 |
P95 周期内响应耗时从小到大排列,顺序处于 95% 位置的分位数值。 |
P99 |
P99 周期内响应耗时从小到大排列,顺序处于 99% 位置的分位数值。 |
P999 |
P999 周期内响应耗时从小到大排列,顺序处于 99.9% 位置的分位数值。 |
配置信息¶
列出当前集群中 Graph、Meta、Storage 服务的所有配置信息。
关于各个服务的配置信息的详情,参见配置管理。
最后更新:
June 20, 2023