集群间数据同步¶
Nebula Graph 支持在集群间进行数据同步,即主集群 A 的数据可以近实时地复制到从集群 B 中,方便用户进行异地灾备或分流,降低数据丢失的风险,保证数据安全。
Enterpriseonly
仅企业版支持本功能。
背景¶
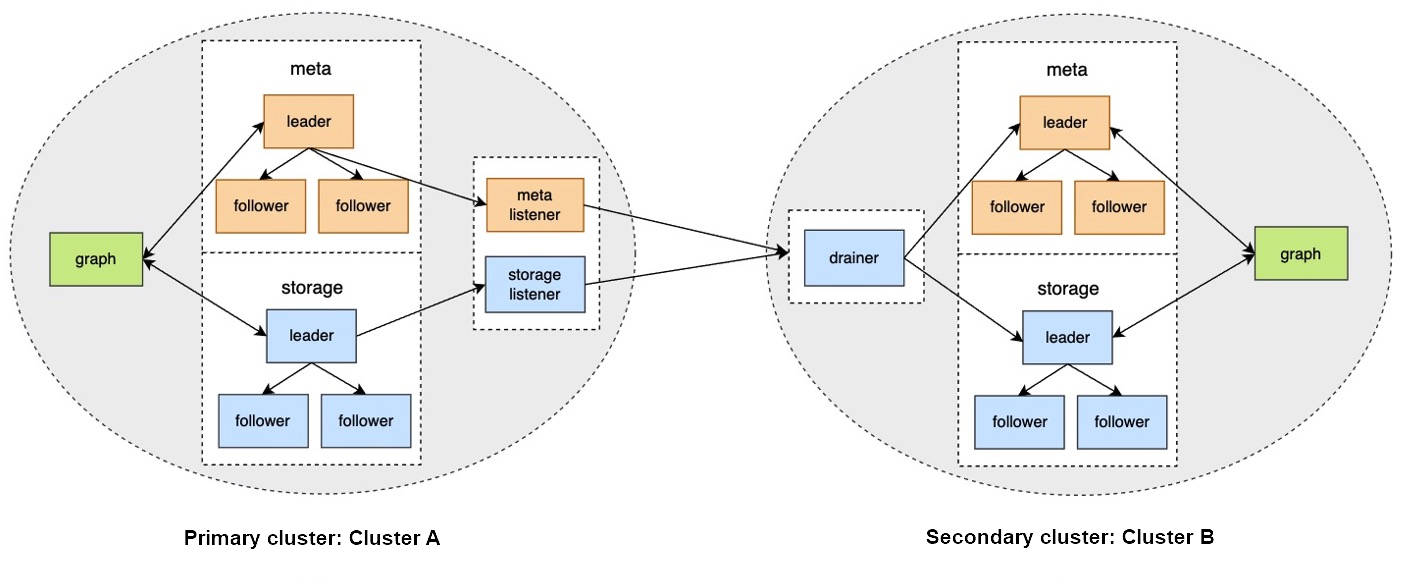
在集群间数据同步方案中,如果主集群 A 的图空间 a 和从集群 B 的图空间 b 建立了同步关系,任何向图空间 a 写入的数据,都会被发送到 Meta listener 或 Storage listener。listener 再将数据发送到 drainer。drainer 接收并存储数据,然后通过从集群的 Meta client 或 Storage client 发送数据至从集群的对应分片。
通过以上流程,最终实现集群间数据同步。
适用场景¶
- 异地灾备:通过数据同步可以实现跨机房或者跨城市的异地灾备。
- 数据迁移:通过切换主从集群的身份,可以实现不停止服务而完成迁移。
- 读写分离:通过设置主集群只写,从集群只读,实现读写分离,降低集群负载,提高稳定性和可用性。
注意事项¶
- 数据同步的基本单位是图空间,即只可以设置从一个图空间到另一个图空间的数据同步。
- 主从集群的数据同步是异步的(近实时)。
- 主从集群之间只支持1 对 1,不支持多个主集群同步到 1 个从集群,也不支持 1 个主集群同步到多个从集群,但是可以通过链式方式同步到多个从集群,例如
主集群->从集群1->从集群2->从集群3。
- Meta listener 监听 Meta 服务,Storage listener 监听 Storage 服务,不可以混用。
- 1 个图空间只有 1 个 Meta listener 和 1 个或多个 Storage listener,这些 listener 可以对应 1 个或多个 drainer。
- listener 服务记录来自主集群的 WAL 或快照,drainer 服务记录来自 listener 的 WAL 和写入从集群的 WAL。这些文件都保存在对应服务的本地。
- 从集群中数据如果不为空,数据同步时可能会导致数据冲突或者数据不一致。建议保持从集群数据为空。
操作步骤¶
准备工作¶
- 准备至少 2 台部署服务的机器。主从集群需要分开部署,listener 和 drainer 可以单独部署,也可以分别部署在主从集群所在机器上,但是会增加集群负载。
- 准备企业版 License 文件。
示例环境¶
主集群A:机器 IP 地址为192.168.10.101,只启动 Graph、Meta、Storage 服务。
从集群B:机器 IP 地址为192.168.10.102,只启动 Graph、Meta、Storage 服务。
listener:机器 IP 地址为192.168.10.103,只启动 Meta listener、Storage listener 服务。
drainer:机器 IP 地址为192.168.10.104,只启动 drainer 服务。
1.搭建主从集群、listener 和 drainer 服务¶
-
在所有机器上安装 Nebula Graph,修改配置文件:
- 主、从集群修改:
nebula-graphd.conf、nebula-metad.conf、nebula-storaged.conf。
- listener 修改:
nebula-metad-listener.conf、nebula-storaged-listener.conf。
- drainer 修改:
nebula-drainerd.conf。
Note
修改配置文件时需要注意:
- 将配置文件的后缀
.default或.production删除。
- 所有配置文件里都需要用真实的机器 IP 地址替换
local_ip的127.0.0.1。
- 所有
nebula-graphd.conf配置文件里设置enable_authorize=true。
- 主从集群填写各自集群的
meta_server_addrs,注意不要错填其他集群的地址。
- listener 的配置文件里
meta_server_addrs填写主集群的机器 IP,meta_sync_listener填写 listener 机器的 IP。
- drainer 的配置文件里
meta_server_addrs填写从集群的机器 IP。
更多配置说明,请参见配置管理。
- 主、从集群修改:
-
在主从集群和 listener 服务的机器上放置 License 文件,路径为安装目录的
share/resources/内。 -
在所有机器的 Nebula Graph 安装目录内启动对应的服务:
- 主、从集群启动命令:
sudo scripts/nebula.service start all。
-
listener 启动命令:
- Meta listener:
sudo bin/nebula-metad --flagfile etc/nebula-metad-listener.conf。
- Storage listener:
sudo bin/nebula-storaged --flagfile etc/nebula-storaged-listener.conf。
- Meta listener:
- drainer 启动命令:
sudo scripts/nebula-drainerd.service start。
- 主、从集群启动命令:
-
登录主集群增加 Storage 主机,检查 listener 服务状态。
nebula> ADD HOSTS 192.168.10.101:9779; nebula> SHOW HOSTS STORAGE; +------------------+------+----------+-----------+--------------+----------------------+ | Host | Port | Status | Role | Git Info Sha | Version | +------------------+------+----------+-----------+--------------+----------------------+ | "192.168.10.101" | 9779 | "ONLINE" | "STORAGE" | "xxxxxxx" | "ent-3.1.0" | +------------------+------+----------+-----------+--------------+----------------------+ nebula> SHOW HOSTS STORAGE LISTENER; +------------------+------+----------+--------------------+--------------+----------------------+ | Host | Port | Status | Role | Git Info Sha | Version | +------------------+------+----------+--------------------+--------------+----------------------+ | "192.168.10.103" | 9789 | "ONLINE" | "STORAGE_LISTENER" | "xxxxxxx" | "ent-3.1.0" | +------------------+------+----------+--------------------+--------------+----------------------+ nebula> SHOW HOSTS META LISTENER; +------------------+------+----------+-----------------+--------------+----------------------+ | Host | Port | Status | Role | Git Info Sha | Version | +------------------+------+----------+-----------------+--------------+----------------------+ | "192.168.10.103" | 9569 | "ONLINE" | "META_LISTENER" | "xxxxxxx" | "ent-3.1.0" | +------------------+------+----------+-----------------+--------------+----------------------+ -
登录从集群增加 Storage 主机,检查 drainer 服务状态。
nebula> ADD HOSTS 192.168.10.102:9779; nebula> SHOW HOSTS STORAGE; +------------------+------+----------+-----------+--------------+----------------------+ | Host | Port | Status | Role | Git Info Sha | Version | +------------------+------+----------+-----------+--------------+----------------------+ | "192.168.10.102" | 9779 | "ONLINE" | "STORAGE" | "xxxxxxx" | "ent-3.1.0" | +------------------+------+----------+-----------+--------------+----------------------+ nebula> SHOW HOSTS DRAINER; +------------------+------+----------+-----------+--------------+----------------------+ | Host | Port | Status | Role | Git Info Sha | Version | +------------------+------+----------+-----------+--------------+----------------------+ | "192.168.10.104" | 9889 | "ONLINE" | "DRAINER" | "xxxxxxx" | "ent-3.1.0" | +------------------+------+----------+-----------+--------------+----------------------+
2.设置服务¶
-
登录主集群,创建图空间
basketballplayer。nebula> CREATE SPACE basketballplayer(partition_num=15, replica_factor=1, vid_type=fixed_string(30)); -
进入图空间
basketballplayer,注册 drainer 服务。nebula> USE basketballplayer; //注册 drainer 服务。 nebula> SIGN IN DRAINER SERVICE(192.168.10.104:9889); //检查是否注册成功。 nebula> SHOW DRAINER CLIENTS; +-----------+------------------+------+ | Type | Host | Port | +-----------+------------------+------+ | "DRAINER" | "192.168.10.104" | 9889 | +-----------+------------------+------+ -
设置 listener 服务。
//设置 listener 服务,待同步的图空间名称为replication_basketballplayer(下文将在从集群中创建)。 nebula> ADD LISTENER SYNC META 192.168.10.103:9569 STORAGE 192.168.10.103:9789 TO SPACE replication_basketballplayer; //查看 listener 状态。 nebula> SHOW LISTENER SYNC; +--------+--------+------------------------+--------------------------------+----------+ | PartId | Type | Host | SpaceName | Status | +--------+--------+------------------------+--------------------------------+----------+ | 0 | "SYNC" | ""192.168.10.103":9569" | "replication_basketballplayer" | "ONLINE" | | 1 | "SYNC" | ""192.168.10.103":9789" | "replication_basketballplayer" | "ONLINE" | | 2 | "SYNC" | ""192.168.10.103":9789" | "replication_basketballplayer" | "ONLINE" | | 3 | "SYNC" | ""192.168.10.103":9789" | "replication_basketballplayer" | "ONLINE" | | 4 | "SYNC" | ""192.168.10.103":9789" | "replication_basketballplayer" | "ONLINE" | | 5 | "SYNC" | ""192.168.10.103":9789" | "replication_basketballplayer" | "ONLINE" | | 6 | "SYNC" | ""192.168.10.103":9789" | "replication_basketballplayer" | "ONLINE" | | 7 | "SYNC" | ""192.168.10.103":9789" | "replication_basketballplayer" | "ONLINE" | | 8 | "SYNC" | ""192.168.10.103":9789" | "replication_basketballplayer" | "ONLINE" | | 9 | "SYNC" | ""192.168.10.103":9789" | "replication_basketballplayer" | "ONLINE" | | 10 | "SYNC" | ""192.168.10.103":9789" | "replication_basketballplayer" | "ONLINE" | | 11 | "SYNC" | ""192.168.10.103":9789" | "replication_basketballplayer" | "ONLINE" | | 12 | "SYNC" | ""192.168.10.103":9789" | "replication_basketballplayer" | "ONLINE" | | 13 | "SYNC" | ""192.168.10.103":9789" | "replication_basketballplayer" | "ONLINE" | | 14 | "SYNC" | ""192.168.10.103":9789" | "replication_basketballplayer" | "ONLINE" | | 15 | "SYNC" | ""192.168.10.103":9789" | "replication_basketballplayer" | "ONLINE" | +--------+--------+------------------------+--------------------------------+----------+ -
登录从集群,创建图空间
replication_basketballplayer。nebula> CREATE SPACE replication_basketballplayer(partition_num=15, replica_factor=1, vid_type=fixed_string(30)); -
进入图空间
replication_basketballplayer,设置 drainer 服务。nebula> USE replication_basketballplayer; //设置 drainer 服务。 nebula> ADD DRAINER 192.168.10.104:9889; //查看 drainer 状态。 nebula> SHOW DRAINERS; +-------------------------+----------+ | Host | Status | +-------------------------+----------+ | ""192.168.10.104":9889" | "ONLINE" | +-------------------------+----------+ -
修改图空间
replication_basketballplayer为只读。Note
修改为只读是防止误操作导致数据不一致。只影响该图空间,其他图空间仍然可以读写。
//设置当前图空间为只读。 nebula> SET VARIABLES read_only=true; //查看当前图空间的读写属性。 nebula> GET VARIABLES read_only; +-------------+--------+-------+ | name | type | value | +-------------+--------+-------+ | "read_only" | "bool" | true | +-------------+--------+-------+
3.验证数据¶
-
登录主集群,创建 Schema,插入数据。
nebula> USE basketballplayer; nebula> CREATE TAG player(name string, age int); nebula> CREATE EDGE follow(degree int); nebula> INSERT VERTEX player(name, age) VALUES "player100":("Tim Duncan", 42); nebula> INSERT VERTEX player(name, age) VALUES "player101":("Tony Parker", 36); nebula> INSERT EDGE follow(degree) VALUES "player101" -> "player100":(95); -
登录从集群,检查数据。
nebula> USE replication_basketballplayer; nebula> SUBMIT JOB STATS; nebula> SHOW STATS; +---------+------------+-------+ | Type | Name | Count | +---------+------------+-------+ | "Tag" | "player" | 2 | | "Edge" | "follow" | 1 | | "Space" | "vertices" | 2 | | "Space" | "edges" | 1 | +---------+------------+-------+ nebula> FETCH PROP ON player "player100" YIELD properties(vertex); +-------------------------------+ | properties(VERTEX) | +-------------------------------+ | {age: 42, name: "Tim Duncan"} | +-------------------------------+ nebula> GO FROM "player101" OVER follow YIELD dst(edge); +-------------+ | dst(EDGE) | +-------------+ | "player100" | +-------------+
停止/重启数据同步¶
数据同步时,listener 会持续发送 WAL 给 drainer。
如果需要停止数据同步,可以使用stop sync命令。此时 listener 会停止向 drainer 发送 WAL。
如果需要重启数据同步,可以使用restart sync命令。此时 listener 会向 drainer 发送停止期间堆积的 WAL。如果 listener 上的 WAL 丢失, listener 会从主集群拉取快照重新进行同步。
切换主从集群¶
如果因为业务需要进行数据迁移,或者灾备恢复后需要切换主从集群,需要手动进行切换。
Note
在切换主从之前需要为新的主集群搭建并启动 listener 服务(示例 IP 为192.168.10.105),为新的从集群搭建并启动 drainer 服务(示例 IP 为192.168.10.106)。
-
登录主集群,取消 drainer 和 listener 服务。
nebula> USE basketballplayer; nebula> SIGN OUT DRAINER SERVICE; nebula> REMOVE LISTENER SYNC; -
设置图空间为只读,防止有新的数据写入主集群,导致数据不一致。
nebula> SET VARIABLES read_only=true; -
登录从集群,设置图空间为可读写,取消 drainer。
nebula> USE replication_basketballplayer; nebula> SET VARIABLES read_only=false; nebula> REMOVE DRAINER; -
将从集群更改为主集群。
nebula> SIGN IN DRAINER SERVICE(192.168.10.106:9889); nebula> ADD LISTENER SYNC META 192.168.10.105:9569 STORAGE 192.168.10.105:9789 TO SPACE basketballplayer; nebula> REMOVE DRAINER; -
登录之前的主集群,将其更改为从集群。
nebula> USE basketballplayer; //修改图空间为可读写,否则无法设置 drainer 服务。 nebula> SET VARIABLES read_only=false; nebula> ADD DRAINER 192.168.10.106:9889; nebula> SET VARIABLES read_only=true;
常见问题¶
主集群中已经有 data 了,从集群可以同步到之前的存量 data 吗?¶
可以。对于主集群中的存量 data,主集群的 listener 会从各个分片的 leader 节点拉取快照,然后以 WAL 的形式发送给 drainer。存量 data 相关的 WAL 发送完毕后,开始发送主集群的增量 data 相关的 WAL 给 drainer。
从集群中已经有 data 了,数据同步会有影响吗?¶
仍然会进行全量数据同步。如果从集群中的数据是主集群数据的子集,最终会数据一致;如果不是主集群数据的子集,从集群不会进行反向同步,而且这部分数据可能会受到影响,请确保主从集群数据不会冲突;建议保持从集群数据为空。
从集群中已经有 Schema 了,数据同步会有影响吗?¶
数据同步时主集群中的 Schema 会覆盖从集群中的 Schema,因此可能导致被覆盖的 Schema 对应的数据失效或者数据不一致。请确保从集群中的 Schema 和主集群中的 Schema 没有冲突。
修改主集群的 Schema 会影响数据同步吗?¶
可能会增加数据同步延迟。因为 Schema 数据和 data 数据是分开处理的(Meta listener 和 Storage listener),data 数据同步时,drainer 会检查自身的 Schema 版本,如果版本大于当前存储的版本,说明 Schema 有更新,这时候会暂缓更新,等待从集群中的 Schema 数据先更新完成。
主从集群的机器数量、副本数量、分片数量需要相同吗?¶
不需要。因为是以图空间为基本单位,主集群不需要知道从集群的架构信息,只需要 listener 将 WAL 发送给 drainer 即可。
如果同步时出现故障,如何修复?¶
可以根据故障节点,进行如下处理:
- 主集群故障:会导致同步暂停,重启主集群服务即可。
- listener/drainer/从集群故障:服务恢复后,会收到前一节点发送的故障期间的 WAL。例如 drainer 故障恢复后,会收到 listener 发送来的故障期间的 WAL。如果用新的节点替换故障的 drainer 节点或从集群,需要将原节点的数据复制到新节点,否则相当于重新同步全量数据。
如何判断数据同步进度?¶
暂无工具进行直接判断。