图数据库的市场概况¶
既然已经讨论了什么是图,接下来让我们进一步认识基于图论和属性图模型发展起来的图数据库。
不同的图数据库在术语方面可能会略有不同,但归根结底都是在讲点、边和属性。至于更多的功能,例如标签、索引、约束、TTL、长任务、存储过程和UDF等这些高级功能,在不同图数据库中,会存在明显的差异。
图数据库用图来存储数据,而图是最接近高度灵活、高性能的数据结构之一。图数据库是一种专门用于存储和检索庞大信息网的存储引擎,它能够高效地将数据存储为点和边,并允许对这些点边结构进行高性能的检索和查询。我们也可以为这些点和边添加属性。
图数据库几乎适用于存储所有领域的数据。因为在几乎所有领域中,事物之间都是由某种相关联的。图数据库支持存储实体之间的丰富关系,并且能够将这些关系完美地呈现出来,而无需像其他建模方式那样,将关系也当成实体存储。因此图数据库能够以最接近对数据直观认知的形式存储数据。
三方机构的统计和预测¶
DB-Engines 的统计¶
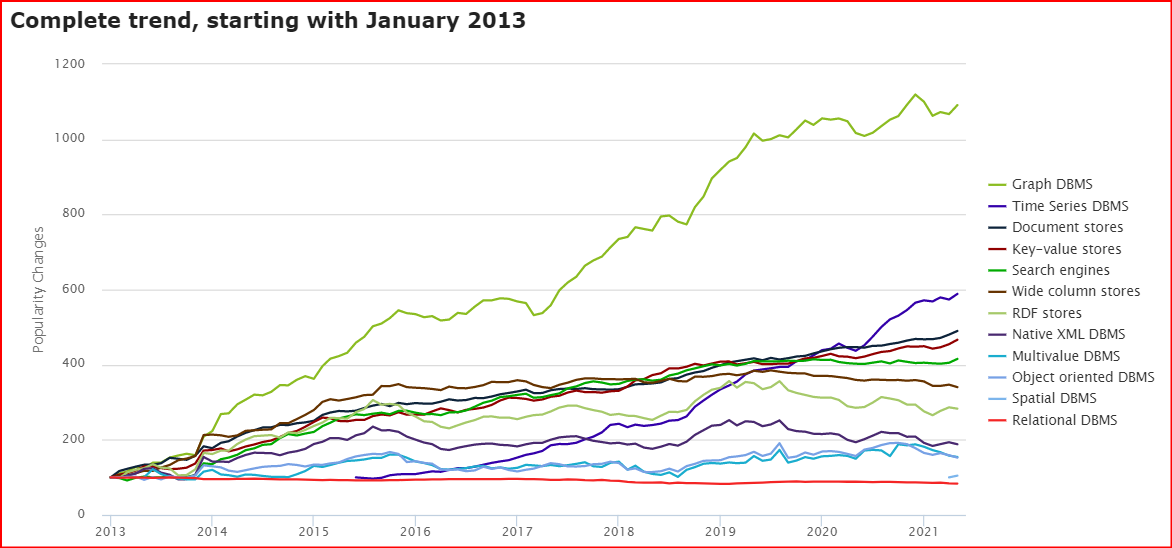
根据世界知名的数据库排名网站DB-Engines.com的统计,图数据库至2013年以来,一直是“增速最快”的数据库类别1。
该网站根据一些指标来统计每种类别的数据库的流行度变化趋势,这些指标包括基于Google等搜索引擎的收录和趋势情况、主要IT技术论坛和社交网站上讨论的技术话题、招聘网站的职位变化等。该网站共收录了371种数据库产品,并分为12个类别。这12个类别中,图数据库这种类别的增速远远快于其他任何的类别。
Gartner 的预测¶
世界顶级智库Gartner早在2013年之前2,就将图数据库作为主要的"商业智能与分析技术趋势"。在那个时候,Big Data正火热的如日中天,数据科学家更是炙手可热的职位。
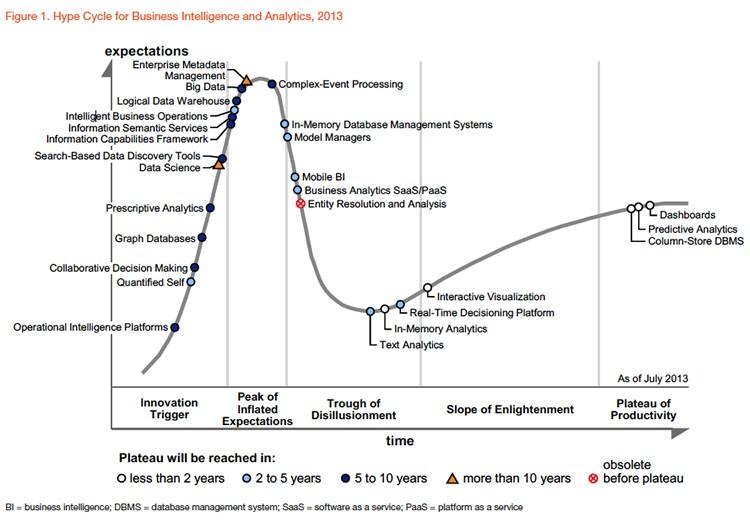
直到最近,图数据库及相关的图技术依旧是"2021年十大数据与分析趋势"3:

趋势八:图技术使一切产生关联(Graph Relates Everything)
图技术已成为许多现代数据和分析能力的基础,能够在不同的数据资产中发现人、地点、事物、事件和位置之间的关系。数据和分析领导者依靠图技术快速回答需要在了解情况并理解多个实体之间的联系和优势的性质后才能回答的复杂业务问题。
Gartner预测,到2025年图技术在数据和分析创新中的占比将从2021年的10%上升到80%。该技术将促进整个企业机构的快速决策。
可以注意到,Gartner 的预测比较好的吻合了 DB-Engines 的统计结论。技术的进步并不是完全线性的,通常会有一段快速发展的泡沫期,然后进入一段平台期,之后由于新的技术的出现产生新一轮的泡沫期,再经历一段平台期。以此往复螺旋形的循环发展。
对于市场规模的预测¶
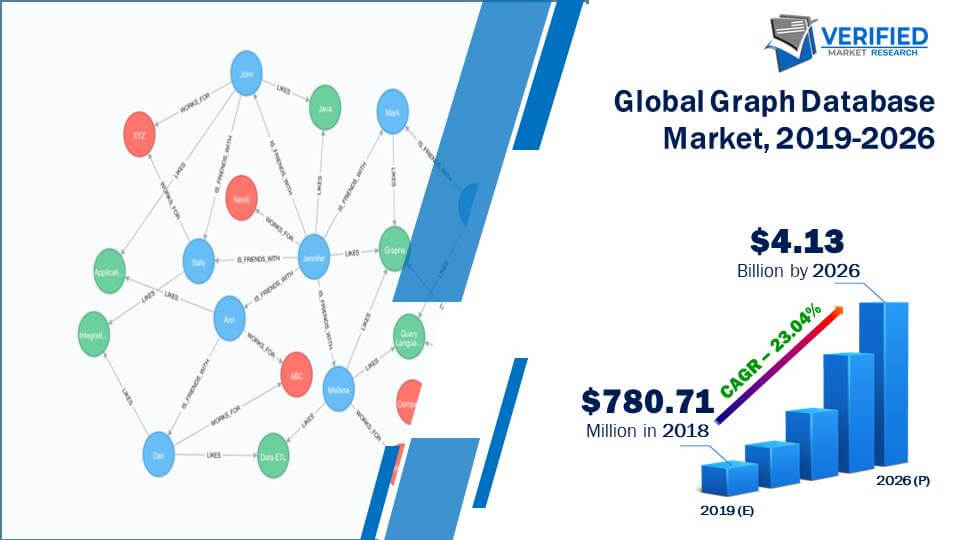
根据 verifiedmarketresearc4, fnfresearch5, marketsandmarkets6, 以及 gartner7 等智库的统计和预测,图数据库市场(包括云服务)规模在2019年大约是8亿美元,将在未来6年保持25%左右的年复合增长(CAGR)至 30-40 亿美元,这大约对应于全球数据库市场 5-10% 的市场份额。
市场参与者¶
(第一代)图数据库的先行者 Neo4j¶
虽然在 1970 年代,人们已经提出了一些类似于"图”的数据模型和产品原型(例如 CODASYL8)和相应的图语言 G/G+ 语言9。但真正能够让“图数据库”这个概念流行起来,不得不说到这个市场最主要的先行者 Neo4j,甚至(标签)属性图和图数据库这两个主要术语就是 Neo4j 最早提出并实践的。
本小节关于Neo4j和其创造的图查询语言Cypher的历史内容主要摘录自 ISO WG3 的工作论文"An overview of the recent history of Graph Query Languages"10 和9,本书作者根据最新两年的进展有删减和更新。
关于图查询语言(Graph Query Language,GQL) 和国际标准的制定
熟悉数据库的读者可能都知道结构化查询语言SQL。通过使用SQL,人们以接近自然语言的方式访问数据库。在 SQL 被广泛采用和标准化之前,关系型数据库的市场是非常碎片和割裂的——各家厂商的产品都有完全不同的接入访问方式,数据库产品自身的开发人员、数据库产品周边工具的开发人员、数据库最终的使用人员,都不得不学习各个厂商的完全不同的产品,在不同产品之间迁移极其困难。当1989年SQL-89标准被制定后,整个关系型数据库的市场快速收敛到SQL-89上。这大大降低了上述各种人员的学习曲线。
类似的,在图数据库领域,图语言(GQL)承担了类似于SQL的作用,是一种用户与图数据库主要的交互方式。但不同于SQL-89这种国际标准,GQL还没有任何国际标准。目前有两种主流的图语言:
Neo4j的Cypher (及其后续——ISO正在制定过程中的 GQL-standard 草案)和Apache TinkerPop的Gremlin。前者通常被称为声明式语言(Declarative query language)——也即用户只需要告诉系统“要什么”,而不管“怎么做”;后者通常被称为命令式语言(Imperative query language),用户会显式地指定系统的操作。
GQL国际标准正在制定过程中。
年表简述¶
- 2000 年,Neo4j 的创始人产生将数据建模成网络(network)的想法。
- 2001 年,Neo4j 开发了最早的核心部分代码。
- 2007 年,Neo4j 开始以一个公司的方式运作。
- 2009 年,Neo4j 团队借鉴 XPath 作为图查询语言,Gremlin11最初也是基于这个想法。
- 2010 年,Neo4j 的员工 Marko Rodriguez 采用术语属性图(Property Graph)来描述 Neo4j 和 Tinkerpop / Gremlin 的数据模型。
- 2011 年,第一个公开发行版本 Neo4j 1.4; 并发布了Cypher的第一个版本。
- 2012 年,Neo4j 1.8 为 Cypher 增加写入图的能力。Neo4j 2.0 增加了标签和索引,Cypher 成为一种声明式的语言。
- 2015 年,Neo4j 将 Cypher 开源为 openCypher。
- 2017 年,ISO WG3 工作组开始讨论如何将属性图查询能力引入 SQL。
- 2018 年 12 月,从 Neo4j 3.5 开始其核心部分转为闭源。
- 2019 年, ISO 正式立项两个项目(ISO/IEC JTC 1 N 14279和ISO/IEC JTC 1/SC 32 N 3228),启动关于图数据库语言国际标准的制定工作。
- 2021 年,Neo4j 完成 F 轮 3.25 亿美元的融资,是整个数据库(包括关系型)历史上最大一轮融资。
Neo4j 的早期历史¶
Neo4j 和属性图这种数据模型,最早构想于 2000 年。Neo4j 的创始人们当时在开发一个媒体管理系统,所使用的数据库的 schema 经常会发生重大变化。为了支持这种灵活性,Neo4j 的联合创始人 Peter Neubauer,受到 Informix Cocoon 的启发,希望将系统能够建模为一种概念相互连接的网络。印度理工学院孟买分校的一群研究生们实现了最早的原型。Neo4j 的联合创始人 Emil Eifrém 和这些学生们花了一周的时间,将 Peter 最初的想法扩展成为一个更抽象的模型:节点通过关系连接,key-value 作为节点和关系的属性。这群人开发了一个 Java API 来和这种数据模型交互,并在关系型数据库之上实现了一个抽象层。
虽然这种网络模型极大的提高了生产力,但是性能一直很差。所以 Neo4j 联合创始人 Johan Svensson 花了不少精力,为这种网络模型实现了一个原生的数据管理系统。这个就成为了 Neo4j。在最初的几年,Neo4j 作为一个内部产品很成功。在 2007 年,Neo4j 的知识产权转移给了一家独立的数据库公司。
在 Neo4j 的第一个公开发行版中(Neo4j 1.4,2011 年),数据模型由节点和有类型的边构成,节点和边都有 key-value 组成的属性。Neo4j 的早期版本没有任何的索引,应用程序只能从根节点开始自己构造查询结构(search structure)。因为这样对于应用程序非常笨重,Neo4j 2.0(2013.12)引入了一个新概念——点上的标签(label)。基于点标签,Neo4j 可以为一些预定义的节点属性建立索引。
"节点"、"关系"、"属性"、"关系只能有一个标签"、"节点可以有零个或者多个标签",以上这些概念构成了 Neo4j 属性图的数据模型定义。随着后来增加的索引功能,让 Cypher 成为了与 Neo4j 交互的主要方式。因为这样应用程序开发者只需要关注于数据本身,而不是上段提到的那个开发者自己构建的查询结构(search structure)。
Gremlin 的创造¶
Gremlin是基于Apache TinkerPop开发的图语言,其风格接近于一连串的函数(过程)调用。最初 Neo4j 的查询方式是通过 Java API。应用程序可以将查询引擎作为库(library)嵌入到应用程序中,然后使用 API 来查询图。
就在这段时间,NOSQL 这个概念开始出现。NOSQL 型的数据库引擎一般用 REST 和 HTTP 来交互和查询。Neo4j 的早期员工 Tobias Lindaaker、Ivarsson、Peter Neubauer 、Marko Rodriguez用 XPath 作为图查询,Groovy 提供循环结构,分支和计算(等图灵完毕的功能)。 这个就是 Gremlin 最初的原型。 2009 年 11 月发布了第一个版本。
后来,Marko 发现同时用两种不同的解析器(XPath 和 Groovy)有很多问题,就将 Gremlin 改为基于 Groovy 的一种领域特定语言(DSL)。
Cypher 的创造¶
Gremlin 和 Neo4j 的 Java API 一样,最初用于表达如何查询数据库的一种过程(Procedural)。它允许更短的语法来表达查询,也允许通过网络远程访问数据库。Gremlin 这种过程式的特性,需要用户知道如何采用最好的办法查询结果,这样对于应用程序开发人员来说仍旧有负担。与此同时,在过去30年中,声明式语言 SQL 取得了极大的成功:SQL 可以将“获取数据的声明方式”和“引擎如何获取数据”相分开,所以 Neo4j 的工程师们希望开发一种声明式的图查询语言。
2010 年,Andrés Taylor 作为工程师加入 Neo4j。受 SQL 启发,他启动了一个项目来开发图查询语言,而这种新语言于 2011 年 Neo4j 1.4 发布,这种新语言就是如今大多数图查询语言的先祖——Cypher 。
Cypher 的语法基础,是用 "ASCII艺术(ASCII art)" 来描述图模式。这种方式最初来源于 Neo4j 工程师团队在源代码中评注如何描述图模式。可以看下图的例子:
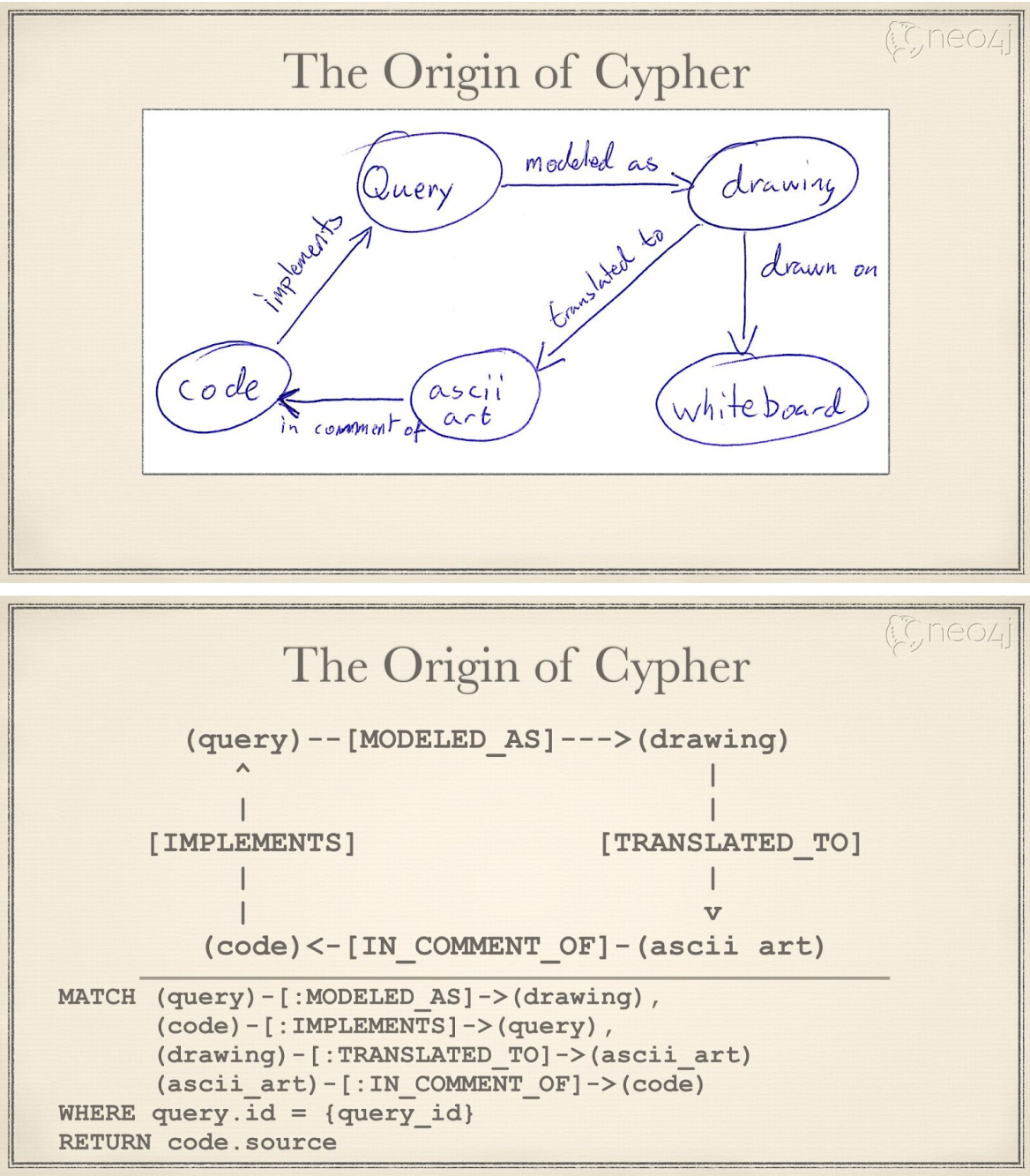
ASCII art 简单说,就是如何用可打印文本来描述点和边。Cypher 文本用()表示点,-[]->表示边。(query)-[modeled as]->(drawing) 来表示起点 query,终点 drawing,边 modeled as,这样一个最简单的图关系(也可以称为图模式)。
Cypher 第一个版本实现了对图的读取,但是需要用户说明从哪些节点开始查询。只有从这些节点开始,才可以支持图的模式匹配。
在后面的版本,2012 年 10 月发布的 Neo4j 1.8 中,Cypher 增加了修改图的能力。但查询还是需要指明从哪些节点开始。
2013 年 12 月,Neo4j 2.0 引入了 label 的概念,label 本质上是个索引。这样,查询引擎就可以利用索引,来选择模式所匹配到的节点,而不需要用户指定开始查询的节点。
随着 Neo4j 的普及,Cypher 有着广泛的开发者群体,在各行各业的得到广泛的使用。至今仍是最受欢迎的图查询语言。
2015 年 9 月,Neo4j 发起成立了 openCypher Implementors Group(oCIG),将 Cypher 开放为 openCypher,通过开源的方式来治理和推进语言自身的演化。
后续¶
Cypher 启发了一系列后续的图查询语言,包括
2015 年,Oracle 发布图引擎PGX使用的图语言PGQL。
2016 年,Linked Data Benchmarking Council, LDBC 是一个行业知名的图性能基准评测机构。LDBC 发布 G-CORE
2018 年,基于 Redis 的图库(library) RedisGraph 采用 Cypher 作为其图语言
2019 年,国际标准组织 ISO 启动两个项目,基于 openCypher, PGQL, GSQL12, and G-CORE 等现有业界成果,启动图语言国际标准的制定过程
2019 年,NebulaGraph 以 openCypher 为基础发布其扩展的图语言 NebulaGraph Query Language, nGQL。

分布式图数据库¶
大约 2005-2010 年,随着 Google 云计算"三驾马车"的发布,各种分布式的架构开始越来越流行,其中就包括以开源方式运作的 Hadoop 和 Cassandra 等。这里包括几个方面的影响:
-
由于数据量和计算量越来越大,相比于单机(例如 Neo4j)或者小型机这种方案,分布式系统的技术和成本优势更加明显;而同时,分布式系统使得应用程序在访问这成千上万台机器时,就如同访问本地的系统一样,不需要在代码层面进行过多改造;
-
开源方式使得更多的人(包括代码开发者、数据科学家、产品经理等)以更加低成本和有效的方式参与新兴的技术,并反馈给社区。
严格说,Neo4j 也提供了不少的分布式的能力,但都和业界意义上的(对等、分片的)分布式系统有较大的不同:
- Neo4j 3.X 要求全量数据必须存放在单机中。虽然其也提供多机之间(Master-slave/slave)做全量复制和高可用,但数据不可切分为不同子图存放。
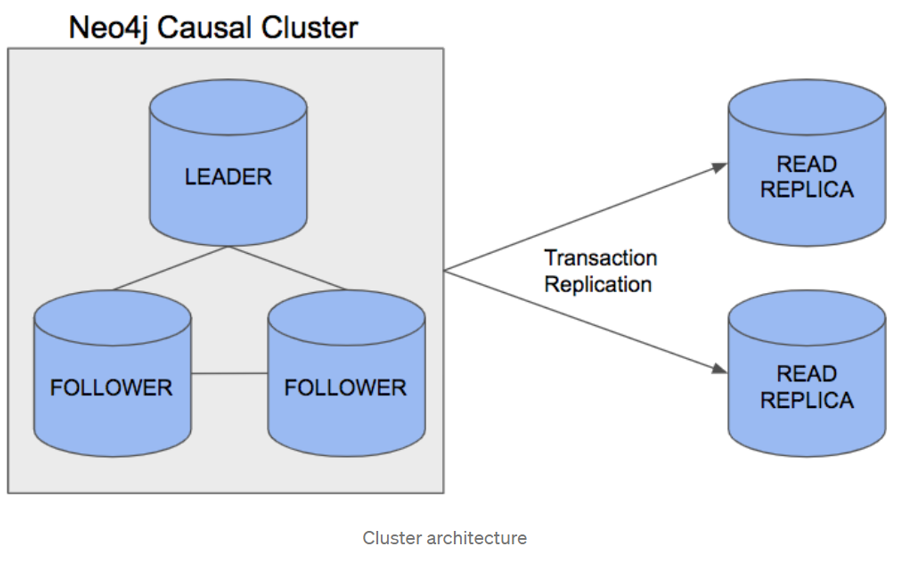
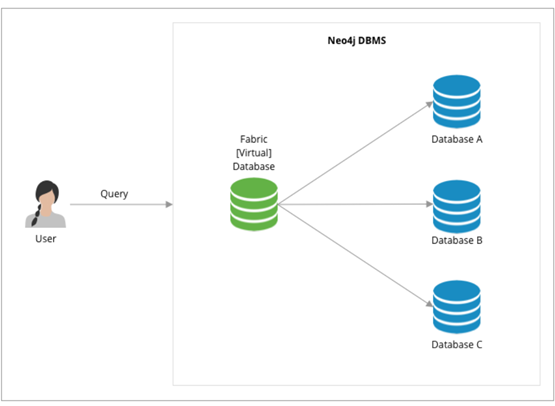
- Neo4j 4.X 允许在不同机器上各存放一部分数据(子图),然后在应用层需通过一定方式拼装后(其称为编织 Fabric)13,将读写分发到各个机器上。这种做法需要应用层代码有大量的参与和工作。例如,设计如何把不同子图应该放置在哪些机器上,如何将从各机器获取的部分结果重新编织为最终的结果。

其语法风格大体是
USE graphA # S1.1 从 Shard A 读
MATCH (movie:Movie)
Return movie.title AS title
UNION # S2. 在代理服务器 Join 结果
USE graphB # S1.2 从 Shard B 读
MATCH (move:Movie)
RETURN movie.title AS title
第二代(分布式)图数据库:Titan 和其后继者 JanusGraph¶
2011 年,Aurelius 公司成立,致力于开发一个开源的分布式图数据库 Titan14。到 2015 年 Titan 的第一个正式版发布,Titan 后端可以支持多种主流的分布式存储架构(例如 Cassandra, HBase, Elasticsearch, BerkeleyDB),并可以复用 Hadoop 生态的诸多便利,前端以 Gremlin 为统一的查询语言。对于程序员使用、开发和社区参与都很方便。大规模的图,可以分片后存放在 HBase 或者 Cassarndar上(这些当时都已经是相对成熟的分布式存储方案),Gremlin 语言虽然略微冗长但相对功能完备。整个方案在当时(2011-2015)体现了不错的竞争力。
下图显示了 2012年 - 2015 年,Titan 和 Neo4j 在 GitHub.com 上 star 的增长情况。
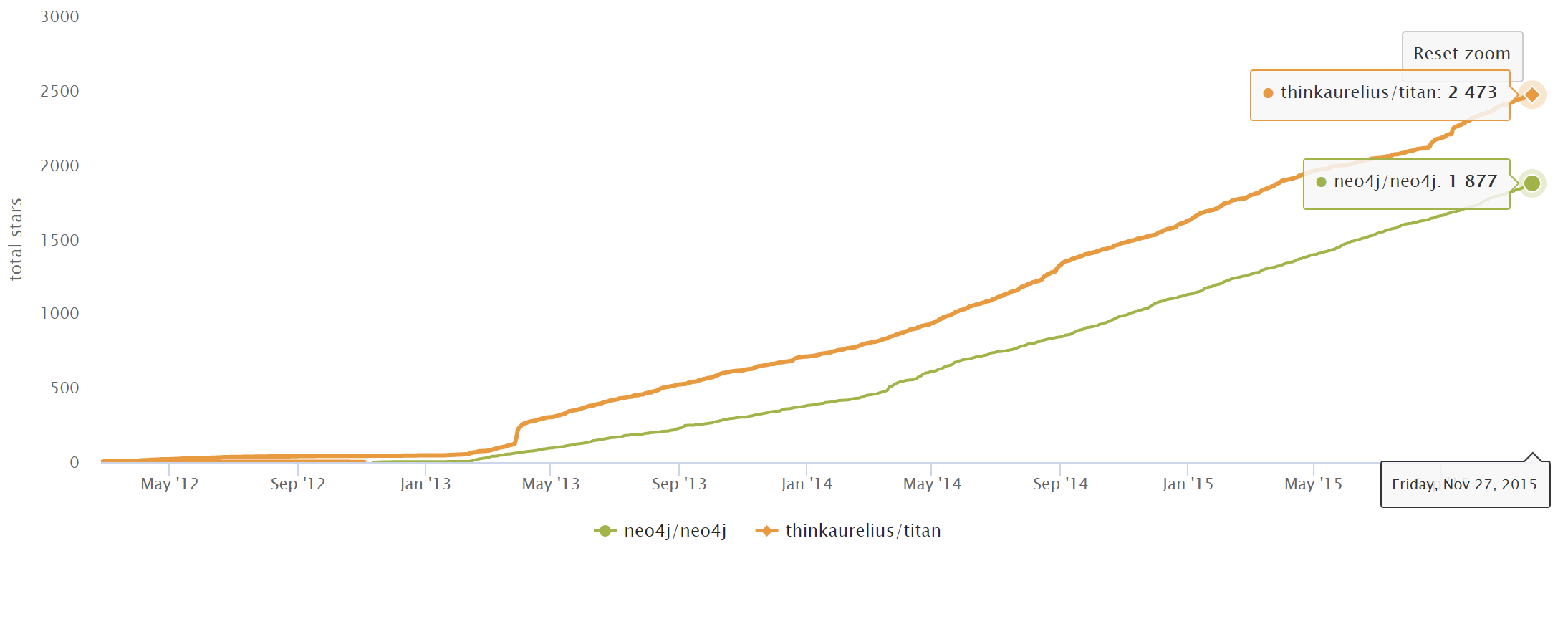
2015 年 Aurelius(Titan) 被 DataStax 收购,这之后 Titan 逐渐转变为一个闭源的商业产品 (DataStax Enterprise Graph)。
在 Aurelius(Titan) 被收购后,市场对于开源分布式的图数据库一直仍有比较强烈的需求,而当时市场上成熟和活跃的产品并不多。大数据时代,数据仍在远快于摩尔定律的速度,源源不断的产生。Linux 基金会以及一些技术巨头(Expero, Google, GRAKN.AI, Hortonworks, IBM and Amazon) 在2017年,复制并分叉(fork)了原有的Titan项目,并启动为一个新项目 JanusGraph15。之后大多数的社区工作,包括开发、测试、发布和推广都逐步转移到了新的 JanusGraph。
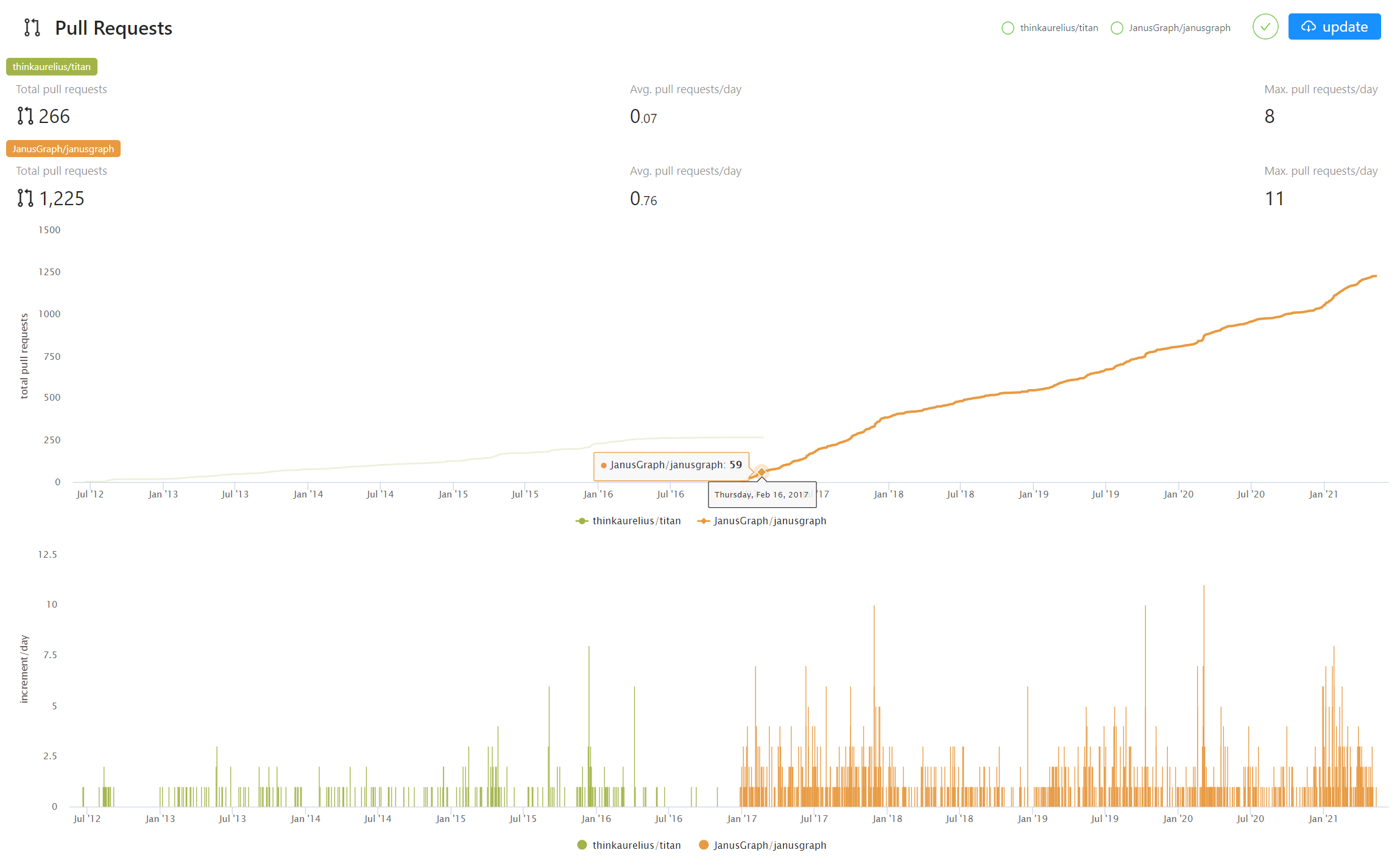
下图显示了两个项目2012-2021年日常代码提交(pull request)的变化情况,可以观察到几点:
-
即使 Aurelius(Titan) 2015 年被收购后,其开源代码仍有一定的活跃度(左侧),但增速已经明显放缓。这体现了社区的力量。
-
新项目 JanusGraph 项目在 2017 年 1 月启动后,其社区迅速活跃起来,短短一年时间就超越了 Titan 过去 5 年累计的 pull request 数量。而与此同时,Titan 开源项目就此停滞。
同期知名产品 OrientDB, TigerGraph, ArangoDB, 和 DGraph¶
此后更多的厂商加入整个市场,除了由Linux基金会托管的 JanusGraph,还有一些由商业公司主导开发的分布式图数据,各方采用的数据模型和访问方式也有明显的不同。 本文不做一一介绍,仅简单列出主要区别。
| 厂商名 | 创立时间 | 核心产品名 | 开源协议 | 数据模型 | 查询语言 |
|---|---|---|---|---|---|
| OrientDB LTD (2017 年 被 SAP 收购) | 2011 | OrientDB | 开源 | 文档 + KV + 图 | OrientDB SQL (基于SQL扩展的图能力) |
| GraphSQL (后改名 TigerGraph) | 2012 | TigerGraph | 商业版本 | 图(分析) | GraphSQL (类SQL风格) |
| ArangoDB GmbH | 2014 | ArangoDB | Apache License 2.0 | 文档 + KV + 图 | AQL (同时操作文档, KV 和图) |
| DGraph Labs | 2016 | DGraph | Apache Public License 2.0 + Dgraph Community License | 原 RDF,后改为 GraphQL | GraphQL+- |
传统巨头微软、亚马逊和甲骨文纷纷入场¶
除了聚焦于图产品的厂商外,传统巨头也纷纷进入这个领域。
Microsoft Azure Cosmos DB16 是一个在微软云上的多模数据库云服务,可以提供SQL、文档、图、key-value等多种能力; Amazon AWS Neptune17 是一种由 AWS 提供图数据库云服务, 可以提供属性图和 RDF 两种数据模型; Oracle graph18 是关系型数据库巨头 Oracle 在图技术与图数据库方向的产品。
新一代开源分布式图数据库 NebulaGraph¶
在下一章,我们将正式介绍新一代开源分布式图数据库 NebulaGraph。
-
https://db-engines.com/en/ranking_categories ↩
-
https://www.yellowfinbi.com/blog/2014/06/yfcommunitynews-big-data-analytics-the-need-for-pragmatism-tangible-benefits-and-real-world-case-165305 ↩
-
https://www.gartner.com/smarterwithgartner/gartner-top-10-data-and-analytics-trends-for-2021/ ↩
-
https://www.verifiedmarketresearch.com/product/graph-database-market/ ↩
-
https://www.globenewswire.com/news-release/2021/01/28/2165742/0/en/Global-Graph-Database-Market-Size-Share-to-Exceed-USD-4-500-Million-By-2026-Facts-Factors.html ↩
-
https://www.marketsandmarkets.com/Market-Reports/graph-database-market-126230231.html ↩
-
https://www.gartner.com/en/newsroom/press-releases/2019-07-01-gartner-says-the-future-of-the-database-market-is-the ↩
-
https://www.amazon.com/Designing-Data-Intensive-Applications-Reliable-Maintainable/dp/1449373321 ↩
-
I. F. Cruz, A. O. Mendelzon, and P. T. Wood. A Graphical Query Language Supporting Recursion. In Proceedings of the Association for Computing Machinery Special Interest Group on Management of Data, pages 323–330. ACM Press, May 1987. ↩↩
-
"An overview of the recent history of Graph Query Languages". Authors: Tobias Lindaaker, U.S. National Expert.Date: 2018-05-14 ↩
-
Gremlin是基于Apache TinkerPop开发的图语言(https://tinkerpop.apache.org/)。 ↩
-
https://docs.tigergraph.com/dev/gsql-ref ↩
-
https://neo4j.com/fosdem20/ ↩
-
https://github.com/thinkaurelius/titan ↩
-
https://github.com/JanusGraph/janusgraph ↩
-
https://azure.microsoft.com/en-us/free/cosmos-db/ ↩
-
https://aws.amazon.com/cn/neptune/ ↩
-
https://www.oracle.com/database/graph/ ↩