LIMIT¶
LIMIT子句限制输出结果的行数。LIMIT在原生 nGQL 语句和 openCypher 兼容语句中的用法有所不同。
- 在原生 nGQL 语句中,一般需要在
LIMIT子句前使用管道符,可以直接在 LIMIT 语句后设置或者省略偏移量参数。
-
在 openCypher 兼容语句中,不允许在
LIMIT子句前使用管道符,可以使用SKIP指明偏移量。Note
在原生 nGQL 或 openCypher 方式中使用
LIMIT时,使用ORDER BY子句限制输出顺序非常重要,否则会输出一个不可预知的子集。
原生 nGQL 语句中的 LIMIT¶
在原生 nGQL 中,LIMIT有通用语法和GO语句中的专属语法。
原生 nGQL 中的通用 LIMIT 语法¶
原生 nGQL 中的通用LIMIT语法与SQL中的LIMIT原理相同。LIMIT子句接收一个或两个参数,参数的值必须是非负整数,且必须用在管道符之后。语法和说明如下:
... | LIMIT [<offset>,] <number_rows>;
| 参数 | 说明 |
|---|---|
offset |
偏移量,即定义从哪一行开始返回。索引从0开始。默认值为0,表示从第一行开始返回。 |
number_rows |
返回的总行数。 |
示例:
# 从结果中返回最前面的 3 行数据。
nebula> LOOKUP ON player YIELD id(vertex)|\
LIMIT 3;
+-------------+
| id(VERTEX) |
+-------------+
| "player100" |
| "player101" |
| "player102" |
+-------------+
# 从排序后结果中返回第 2 行开始的 3 行数据。
nebula> GO FROM "player100" OVER follow REVERSELY \
YIELD properties($$).name AS Friend, properties($$).age AS Age \
| ORDER BY $-.Age, $-.Friend \
| LIMIT 1, 3;
+-------------------+-----+
| Friend | Age |
+-------------------+-----+
| "Danny Green" | 31 |
| "Aron Baynes" | 32 |
| "Marco Belinelli" | 32 |
+-------------------+-----+
GO 语句中的 LIMIT¶
GO语句中的LIMIT除了支持原生 nGQL 中的通用语法外,还支持根据边限制输出结果数量。
语法:
<go_statement> LIMIT <limit_list>;
limit_list是一个列表,列表中的元素必须为自然数,且元素数量必须与GO语句中的STEPS的最大数相同。下文以GO 1 TO 3 STEPS FROM "A" OVER * LIMIT <limit_list>为例详细介绍LIMIT的这种用法。
- 列表
limit_list必须包含 3 个自然数元素,例如GO 1 TO 3 STEPS FROM "A" OVER * LIMIT [1,2,4]。 LIMIT [1,2,4]中的1表示系统在第一步时自动选择 1 条边继续遍历,2表示在第二步时选择 2 条边继续遍历,4表示在第三步时选择 4 条边继续遍历。- 因为
GO 1 TO 3 STEPS表示返回第一到第三步的所有遍历结果,因此下图中所有红色边和它们的原点与目的点都会被这条GO语句匹配上,而黄色边表示GO语句遍历时没有选择的路径。如果不是GO 1 TO 3 STEPS而是GO 3 STEPS,则只会匹配上第三步的红色边和它们两端的点。
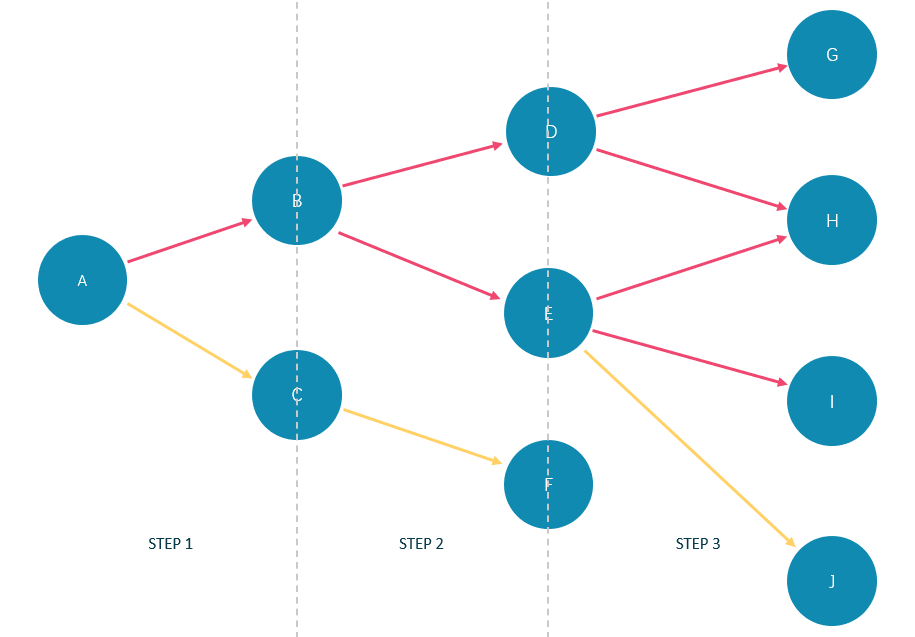
在 basketballplayer 数据集中的执行示例如下:
nebula> GO 3 STEPS FROM "player100" \
OVER * \
YIELD properties($$).name AS NAME, properties($$).age AS Age \
LIMIT [3,3,3];
+-----------------+----------+
| NAME | Age |
+-----------------+----------+
| "Tony Parker" | 36 |
| "Manu Ginobili" | 41 |
| "Spurs" | __NULL__ |
+-----------------+----------+
nebula> GO 3 STEPS FROM "player102" OVER * BIDIRECT\
YIELD dst(edge) \
LIMIT [rand32(5),rand32(5),rand32(5)];
+-------------+
| dst(EDGE) |
+-------------+
| "player100" |
| "player100" |
+-------------+
openCypher 兼容语句中的 LIMIT¶
在MATCH等 openCypher 兼容语句中使用 LIMIT 不需要加管道符。语法和说明如下:
... [SKIP <offset>] [LIMIT <number_rows>];
| 参数 | 说明 |
|---|---|
offset |
偏移量,即定义从哪一行开始返回。索引从0开始。默认值为0,表示从第一行开始返回。 |
number_rows |
返回的总行数量。 |
offset和number_rows可以使用表达式,但是表达式的结果必须是非负整数。
Note
两个整数组成的分数表达式会自动向下取整。例如8/6向下取整为 1。
单独使用 LIMIT¶
LIMIT可以单独使用,返回指定数量的结果。
nebula> MATCH (v:player) RETURN v.player.name AS Name, v.player.age AS Age \
ORDER BY Age LIMIT 5;
+-------------------------+-----+
| Name | Age |
+-------------------------+-----+
| "Luka Doncic" | 20 |
| "Ben Simmons" | 22 |
| "Kristaps Porzingis" | 23 |
| "Giannis Antetokounmpo" | 24 |
| "Kyle Anderson" | 25 |
+-------------------------+-----+
单独使用 SKIP¶
SKIP可以单独使用,用于设置偏移量,返回指定位置之后的数据。
nebula> MATCH (v:player{name:"Tim Duncan"}) --> (v2) \
RETURN v2.player.name AS Name, v2.player.age AS Age \
ORDER BY Age DESC SKIP 1;
+-----------------+-----+
| Name | Age |
+-----------------+-----+
| "Manu Ginobili" | 41 |
| "Tony Parker" | 36 |
+-----------------+-----+
nebula> MATCH (v:player{name:"Tim Duncan"}) --> (v2) \
RETURN v2.player.name AS Name, v2.player.age AS Age \
ORDER BY Age DESC SKIP 1+1;
+---------------+-----+
| Name | Age |
+---------------+-----+
| "Tony Parker" | 36 |
+---------------+-----+
同时使用 SKIP 与 LIMIT¶
同时使用SKIP与LIMIT可以返回从指定位置开始的指定数量的数据。
nebula> MATCH (v:player{name:"Tim Duncan"}) --> (v2) \
RETURN v2.player.name AS Name, v2.player.age AS Age \
ORDER BY Age DESC SKIP 1 LIMIT 1;
+-----------------+-----+
| Name | Age |
+-----------------+-----+
| "Manu Ginobili" | 41 |
+-----------------+-----+
最后更新:
2025年4月21日