Graph 服务¶
Graph 服务主要负责处理查询请求,包括解析查询语句、校验语句、生成执行计划以及按照执行计划执行四个大步骤,本文将基于这些步骤介绍 Graph 服务。
Graph 服务架构¶
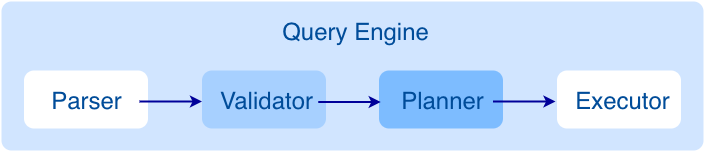
查询请求发送到 Graph 服务后,会由如下模块依次处理:
-
Parser:词法语法解析模块。
-
Validator:语义校验模块。
-
Planner:执行计划与优化器模块。
-
Executor:执行引擎模块。
Parser¶
Parser 模块收到请求后,通过 Flex(词法分析工具)和 Bison(语法分析工具)生成的词法语法解析器,将语句转换为抽象语法树(AST),在语法解析阶段会拦截不符合语法规则的语句。
例如GO FROM "Tim" OVER like WHERE properties(edge).likeness > 8.0 YIELD dst(edge)语句转换的 AST 如下。
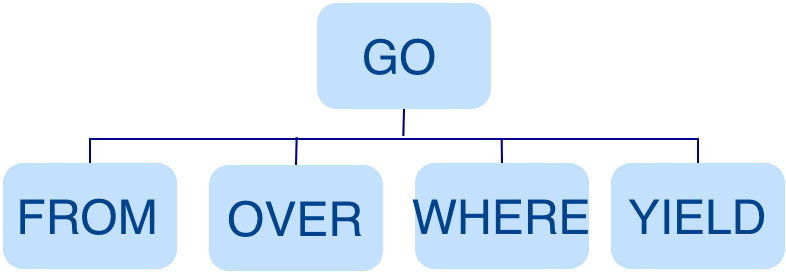
Validator¶
Validator 模块对生成的 AST 进行语义校验,主要包括:
- 校验元数据信息
校验语句中的元数据信息是否正确。
例如解析
OVER、WHERE和YIELD语句时,会查找 Schema 校验 Edge type、Tag 的信息是否存在,或者插入数据时校验插入的数据类型和 Schema 中的是否一致。
- 校验上下文引用信息
校验引用的变量是否存在或者引用的属性是否属于变量。
例如语句
$var = GO FROM "Tim" OVER like YIELD dst(edge) AS ID; GO FROM $var.ID OVER serve YIELD dst(edge),Validator 模块首先会检查变量var是否定义,其次再检查属性ID是否属于变量var。
- 校验类型推断
推断表达式的结果类型,并根据子句校验类型是否正确。
例如
WHERE子句要求结果是bool、null或者empty。
- 校验
*代表的信息查询语句中包含
*时,校验子句时需要将*涉及的 Schema 都进行校验。例如语句
GO FROM "Tim" OVER * YIELD dst(edge), properties(edge).likeness, dst(edge),校验OVER子句时需要校验所有的 Edge type,如果 Edge type 包含like和serve,该语句会展开为GO FROM "Tim" OVER like,serve YIELD dst(edge), properties(edge).likeness, dst(edge)。
- 校验输入输出
校验管道符(|)前后的一致性。
例如语句
GO FROM "Tim" OVER like YIELD dst(edge) AS ID | GO FROM $-.ID OVER serve YIELD dst(edge),Validator 模块会校验$-.ID在管道符左侧是否已经定义。
校验完成后,Validator 模块还会生成一个默认可执行,但是未进行优化的执行计划,存储在目录 src/planner 内。
Planner¶
如果配置文件 nebula-graphd.conf 中 enable_optimizer 设置为 false,Planner 模块不会优化 Validator 模块生成的执行计划,而是直接交给 Executor 模块执行。
如果配置文件 nebula-graphd.conf中enable_optimizer 设置为 true,Planner 模块会对 Validator 模块生成的执行计划进行优化。如下图所示。
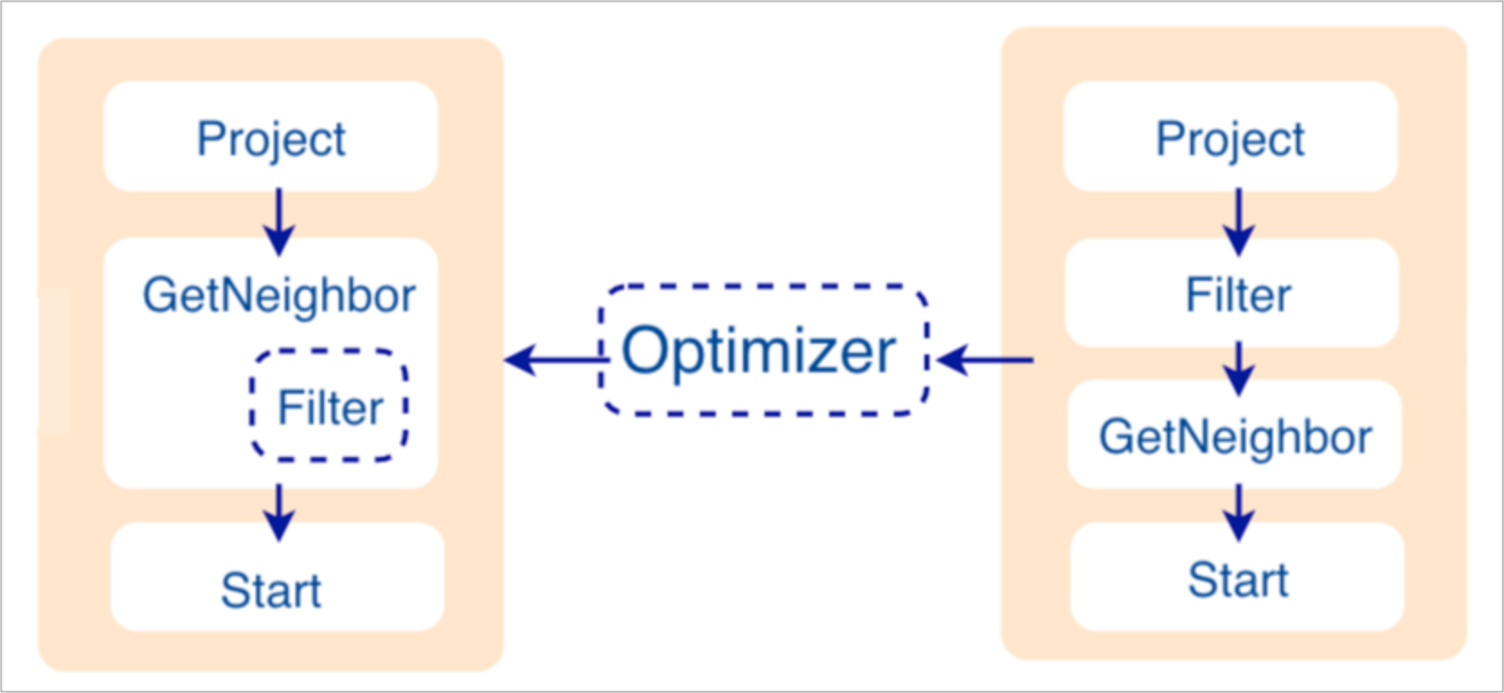
- 优化前
如上图右侧未优化的执行计划,每个节点依赖另一个节点,例如根节点
Project依赖Filter、Filter依赖GetNeighbor,最终找到叶子节点Start,才能开始执行(并非真正执行)。在这个过程中,每个节点会有对应的输入变量和输出变量,这些变量存储在一个哈希表中。由于执行计划不是真正执行,所以哈希表中每个 key 的 value 值都为空(除了
Start节点,起始数据会存储在该节点的输入变量中)。哈希表定义在仓库nebula-graph内的src/context/ExecutionContext.cpp中。例如哈希表的名称为
ResultMap,在建立Filter这个节点时,定义该节点从ResultMap["GN1"]中读取数据,然后将结果存储在ResultMap["Filter2"]中,依次类推,将每个节点的输入输出都确定好。
- 优化过程
Planner 模块目前的优化方式是 RBO(rule-based optimization),即预定义优化规则,然后对 Validator 模块生成的默认执行计划进行优化。新的优化规则 CBO(cost-based optimization)正在开发中。优化代码存储在仓库
nebula-graph的目录src/optimizer/内。RBO 是一个自底向上的探索过程,即对于每个规则而言,都会由执行计划的根节点(示例是
Project)开始,一步步向下探索到最底层的节点,在过程中查看是否可以匹配规则。如上图所示,探索到节点
Filter时,发现依赖的节点是GetNeighbor,匹配预先定义的规则,就会将Filter融入到GetNeighbor中,然后移除节点Filter,继续匹配下一个规则。在执行阶段,当算子GetNeighbor调用 Storage 服务的接口获取一个点的邻边时,Storage 服务内部会直接将不符合条件的边过滤掉,这样可以极大地减少传输的数据量,该优化称为过滤下推。
Executor¶
Executor 模块包含调度器(Scheduler)和执行器(Executor),通过调度器调度执行计划,让执行器根据执行计划生成对应的执行算子,从叶子节点开始执行,直到根节点结束。如下图所示。
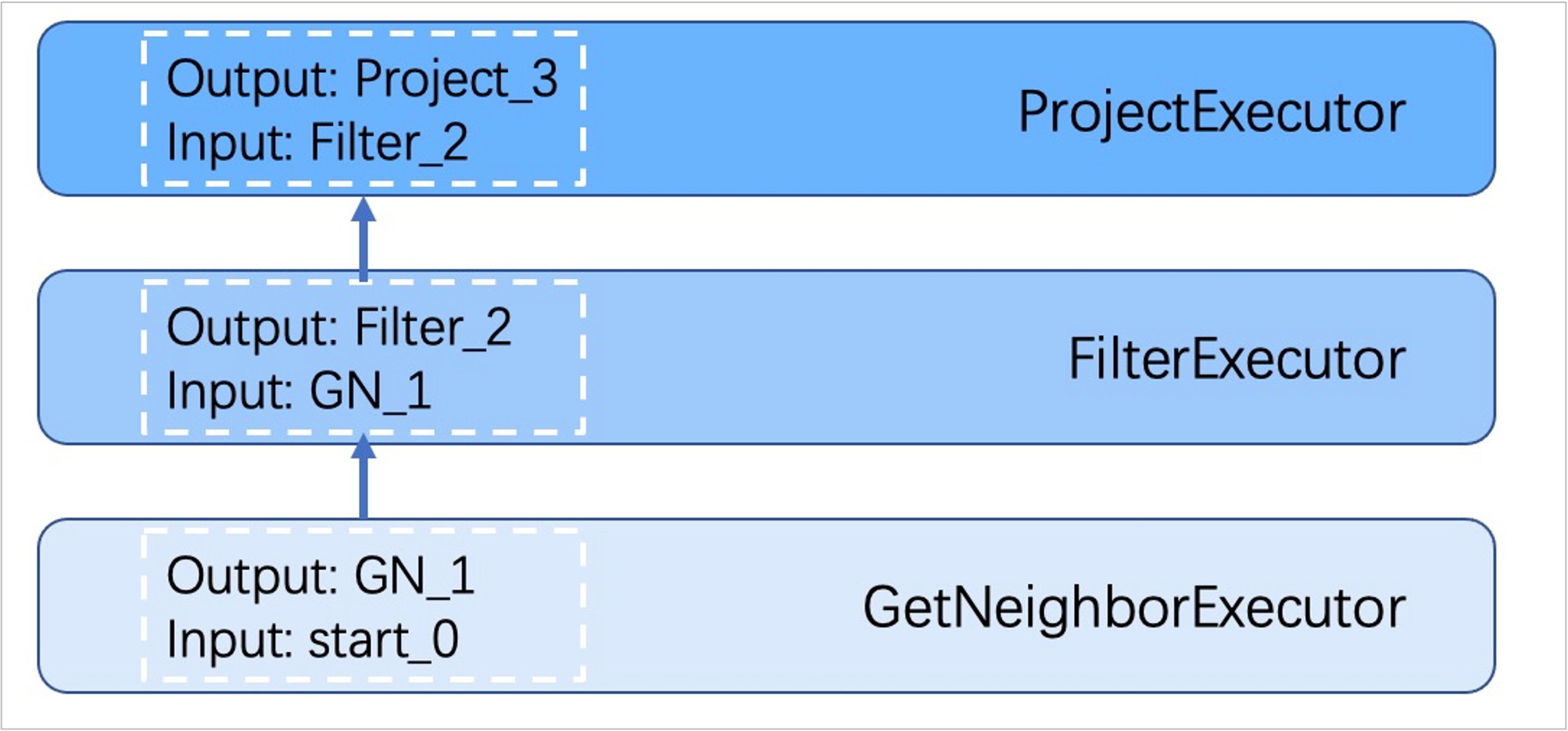
每一个执行计划节点都一一对应一个执行算子,节点的输入输出在优化执行计划时已经确定,每个算子只需要拿到输入变量中的值进行计算,最后将计算结果放入对应的输出变量中即可,所以只需要从节点 Start 一步步执行,最后一个算子的输出变量会作为最终结果返回给客户端。
代码结构¶
NebulaGraph 的代码层次结构如下:
|--src
|--graph
|--context //校验期和执行期上下文
|--executor //执行算子
|--gc //垃圾收集器
|--optimizer //优化规则
|--planner //执行计划结构
|--scheduler //调度器
|--service //对外服务管理
|--session //会话管理
|--stats //运行指标
|--util //基础组件
|--validator //语句校验
|--visitor //visitor表达式
视频¶
用户也可以通过视频全方位了解 NebulaGraph 的查询引擎。
- nMeetup·上海 |全面解析 Query Engine(33 分 30 秒)