图建模设计¶
本文介绍在NebulaGraph项目中成功应用的一些图建模和系统设计的通用建议。
Note
本文建议是通用的,在特定领域有例外,请结合实际业务情况进行图建模。
以性能为第一目标进行建模¶
目前NebulaGraph没有完美的建模方法,如何建模取决于想从数据中挖掘的内容。分析数据并根据业务模型创建方便直观的数据模型,测试模型并优化,逐渐适应业务。为了更好的性能,用户可以多次更改或重新设计模型。
设计和评估最重要的查询语句¶
在测试环节中,通常会验证各种各样的查询语句,以全面评估系统能力。但在大多数生产场景下,每个集群被频繁调用的查询语句的类型并不会太多;根据 20-80 原则,针对重要的查询语句进行建模优化。
避免全量扫描¶
通过属性索引或者 VID 来先定位到某个(些)点或者边,然后开始图遍历;对于有些查询,它们只给定了一个子图或者路径的(正则)模式,但无法通过属性索引或者 VID 定位到遍历起始的点边,而期望找到库中全部满足该模式的子图,这样的查询是通过全量扫描实现的,这样的性能会很差。NebulaGraph没有实现对于子图或者路径的图结构的索引。
Tag 与 Edge type 之间没有绑定关系¶
任何 Tag 可以与任何 Edge type 相关联,完全交由应用程序控制。不需要在NebulaGraph中预先定义,也没有命令获取哪些 Tag 与哪些 Edge type 相关联。
Tag/Edge type 预先定义了一组属性¶
建立 Tag(或者 Edge type)时,需要指定对应的属性。通常称为 Schema。
区分“经常改变的部分”和“不经常改变的部分”¶
改变指的是业务模型和数据模型上的改变(元信息),不是数据自身的改变。
一些图数据库产品是 schema-free 的设计,所以在数据模型上,不论是图拓扑结构还是属性,都可以非常自由。属性可以建模转变为图拓扑,反之亦然。这类系统通常对于图拓扑的访问有特别的优化。
而NebulaGraph 3.5.0 是强 Schema 的(行存型)系统,这意味着业务数据模型中的部分是“不应该经常改变的”,例如属性 Schema 应该避免改变。类似于 MySQL 中 ALTER TABLE 是应该尽量避免的操作。
而点及邻边可以非常低成本的增删,因此可以将业务模型中“经常改变的部分”建模成点或边(关系),而不是属性 Schema。
例如,在一个业务模型中,人的属性是相对固定的,例如“年龄”,“性别”,“姓名”。而“通信好友”,“出入场所”,“交易账号”,“登录设备”等是相对容易改变的。前者适合建模为属性,后者适合建模为点或边。
自环¶
NebulaGraph是强 Schema 类型系统,使用ALTER TAG的开销很大,而且也不支持List类型属性,当用户需要为点添加一些临时属性或者List类型的属性时,可以先创建包含所需属性的边类型,然后为点插入一条或多条指向自身的边。查询时只需要查询指向自己的边属性。如下图所示。
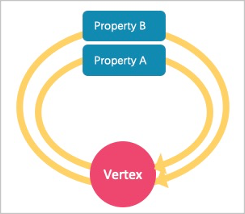
示例:
如果要检索点的临时属性,请从自环边中获取。例如:
//创建边类型并插入自环属性。
nebula> CREATE EDGE IF NOT EXISTS temp(tmp int);
nebula> INSERT EDGE temp(tmp) VALUES "player100"->"player100"@1:(1);
nebula> INSERT EDGE temp(tmp) VALUES "player100"->"player100"@2:(2);
nebula> INSERT EDGE temp(tmp) VALUES "player100"->"player100"@3:(3);
//插入数据后,可以通过查询语句查询,例如:
nebula> GO FROM "player100" OVER temp YIELD properties(edge).tmp;
+----------------------+
| properties(EDGE).tmp |
+----------------------+
| 1 |
| 2 |
| 3 |
+----------------------+
//如果需要返回结果为List,可以通过函数实现,例如:
nebula> MATCH (v1:player)-[e:temp]->() return collect(e.tmp);
+----------------+
| collect(e.tmp) |
+----------------+
| [1, 2, 3] |
+----------------+
对于自环的操作没有封装任何的语法糖,操作方式与普通的边无异。
- NebulaGraph自环小科普(2 分 54 秒)
悬挂边¶
悬挂边 (Dangling edge) 是指一条起点或者终点不存在于数据库中的边。
在NebulaGraph 3.5.0中,有两种情况可能会出现悬挂边。
第一种情况:在起点和终点插入之前,用 INSERT EDGE 语句插入一条边。
第二种情况:使用 DELETE VERTEX 语句删除点的时候,没有使用WITH EDGE选项。此时系统默认不删除该点关联的出边和入边,这些边将变成悬挂边。
NebulaGraph 3.5.0 的数据模型中,由于设计允许图中存在“悬挂边”;没有 openCypher 中的 MERGE 语句。对于悬挂边的保证完全依赖应用层面。用户可以使用 GO 和 LOOKUP 语句查询到悬挂边,但无法使用 MATCH 语句查询到悬挂边。
示例:
// 插入起点为“11”,终点为“13”并且都不存在于数据库中的悬挂边
nebula> CREATE EDGE IF NOT EXISTS e1 (name string, age int);
nebula> INSERT EDGE e1 (name, age) VALUES "11"->"13":("n1", 1);
// 使用 GO 语句查询
nebula> GO FROM "11" over e1 YIELD properties(edge);
+----------------------+
| properties(EDGE) |
+----------------------+
| {age: 1, name: "n1"} |
+----------------------+
// 使用 LOOKUP 语句查询
nebula> LOOKUP ON e1 YIELD EDGE AS r;
+-------------------------------------------------------+
| r |
+-------------------------------------------------------+
| [:e2 "11"->"13" @0 {age: 1, name: "n1"}] |
+-------------------------------------------------------+
// 使用 MATCH 查询,不能查询到悬挂边
nebula> MATCH ()-[e:e1]->() RETURN e;
+---+
| e |
+---+
+---+
Empty set (time spent 3153/3573 us)
- NebulaGraph的悬挂边小科普(2 分 28 秒)
广度优先大于深度优先¶
- NebulaGraph基于图拓扑结构进行深度图遍历的性能较低,广度优先遍历以及获取属性的性能较好。例如,模型 a 包括姓名、年龄、眼睛颜色三种属性,建议创建一个 Tag
person,然后为它添加姓名、年龄、眼睛颜色的属性。如果创建一个包含眼睛颜色的 Tag 和一个 Edge typehas,然后创建一个边用来表示人拥有的眼睛颜色,这种建模方法会降低遍历性能。
- “通过边属性获取边”的性能与“通过点属性获取点”的性能是接近的。在一些数据库中,会建议将边上的属性重新建模为中间节点的属性:例如
(src)-[edge {P1, P2}]->(dst),edge上有属性P1, P2,会建议建模为(src)-[edge1]->(i_node {P1, P2})-[edge2]->(dst)。在NebulaGraph 3.5.0 中可以直接使用(src)-[edge {P1, P2}]->(dst),减少遍历深度有助于性能。
边的方向¶
查询时,如果需要使用边的逆向查询,可以用如下语法:
(dst)<-[edge]-(src) 或者 GO FROM dst REVERSELY;
如果不关心边的方向,可以使用如下语法:
(src)-[edge]-(dst) 或者 GO FROM src BIDIRECT;
因此,通常同一条边没有必要反向再冗余插入一次。
合理设置 Tag 属性¶
在图建模中,请将一组类似的平级属性放入同一个 Tag,即按不同概念进行分组。
正确使用索引¶
使用属性索引可以通过属性查找到 VID。但是索引会导致写性能大幅下降,只有在根据点或边的属性定位点或边时才使用索引。
合理设计 VID¶
参考点 VID 一节。
长文本¶
为边创建属性时请勿使用长文本:这些属性会被存储 2 份,导致写入放大问题(write amplification)。此时建议将长文本放在 HBase/ES 中,将其地址存放在NebulaGraph中。
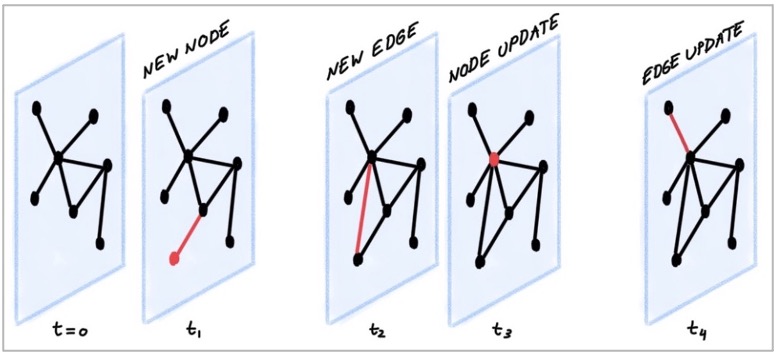
关于支持动态图(时序图)¶
在某些场景下,图需要同时带有时序信息,以描述整个图的结构随着时间变化的情况 1。
NebulaGraph 3.5.0 的边可以使用 Rank 字段存放时间信息 (int64),但是点上没有字段可以存放时间信息(存放在属性会被新写入覆盖)。一个折中的办法是在点上设计自己指向自己的自环,并将时间信息放置在自环的 Rank 上。
一些免费的建模工具¶
-
https://blog.twitter.com/engineering/en_us/topics/insights/2021/temporal-graph-networks ↩