导入导出工具概述¶
导入工具¶
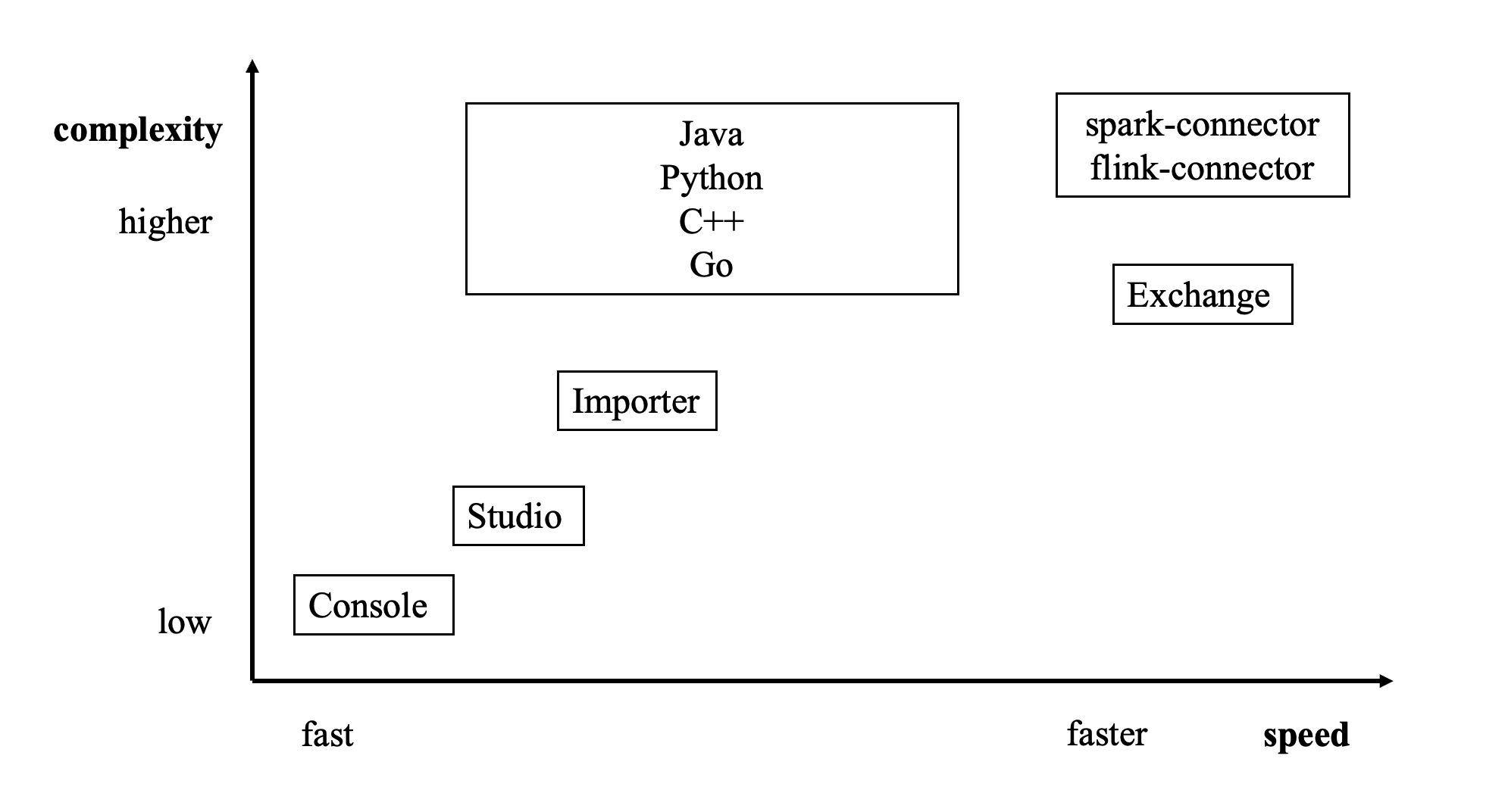
有多种方式可以将数据写入NebulaGraph master:
- 使用命令行 -f 的方式导入:可以导入少量准备好的 nGQL 文件,适合少量手工测试数据准备。
- 使用 Studio 导入:可以用过浏览器导入本机多个 CSV 文件,格式有限制。
- 使用 Importer 导入:导入单机多个 CSV 文件,大小没有限制,格式灵活。适合十亿条数据以内的场景。
- 使用 Exchange 导入:从 Neo4j、Hive、MySQL 等多种源分布式导入,需要有 Spark 集群。适合十亿条数据以上的场景。
- 使用 Spark-connector/Flink-connector 读写 API:这种方式需要编写少量代码来使用 Spark/Flink 连接器提供的 API。
- 使用 C++/GO/Java/Python SDK:编写程序的方式导入,需要有一定编程和调优能力。
下图给出了几种方式的定位:
导出工具¶
- 使用 Spark-connector/Flink-connector 读写 API:这种方式需要编写少量代码来使用 Spark/Flink 连接器提供的 API。
-
使用 Exchange 导出功能将数据导出至 CSV 文件或另一个图空间(支持不同 NebulaGraph 集群)中。
Enterpriseonly
仅企业版 Exchange 提供导出功能。如需企业版,请联系我们。
{kind=link}
最后更新:
2025年8月4日