工作流示例¶
本文介绍如何创建一个简单的工作流。
前提条件¶
- 已有数据源。数据源可以是 NebulaGraph 中的数据或者 HDFS 上的 CSV 文件。
- 已完成资源配置。
新增工作流¶
以 MATCH 语句MATCH (v1:player)--(v2) RETURN id(v1), id(v2);的结果做为 PageRank 算法的输入,介绍如何创建一个简单的工作流。
-
在 Explorer 页面顶部的导航栏中,单击 Workflow。
-
在工作流标签页单击新建工作流,进入流程画布页面。
-
在左侧组件库列表里选择查询->Query,按住左键拖拽至画布中,单击该图查询组件,在右侧弹出的工作流配置面板中进行如下设置。
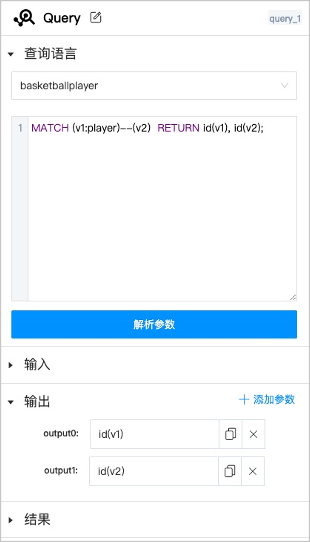
配置项 说明 Query 单击  可以修改组件名称,方别识别。
可以修改组件名称,方别识别。查询语言 选择执行nGQL语句的图空间,以及填写nGQL语句。填写语句后单击解析参数,会在输出里展示返回的列名。 输入 设置自定义参数,可以用于参数化查询。单击添加参数可以增加更多自定义参数。 输出 解析查询语言得到的返回结果列名。可以修改名称,相当于用 AS设置列的别名。结果 设置结果的保存位置。为方便其他算法调用结果,图查询组件的结果只支持保存在 HDFS 上。 Note
连接锚点显示为黄色,表示可选,可以自行设置或者由其他任意组件提供输入。
-
在左侧组件库列表里选择节点重要度->PageRank,按住左键拖拽至画布中,将图查询组件的
output0锚点连接至图计算组件的input0锚点,output1锚点连接至input1锚点。
如果串联使用多个图查询组件,需要自行添加参数化文本。例如语句
GO FROM ${id} OVER follow YIELD dst(vertex),填写语句后单击解析参数,图查询组件中会显示黄色锚点表示${id}。前一个图查询组件的输出锚点可以连接至该黄色锚点作为后一个组件的输入。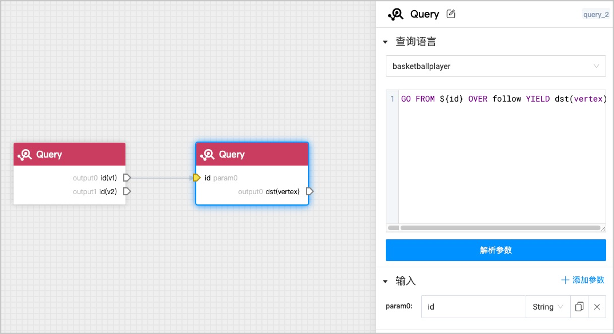
-
单击该图计算组件,在右侧弹出的工作流配置面板中进行如下设置。
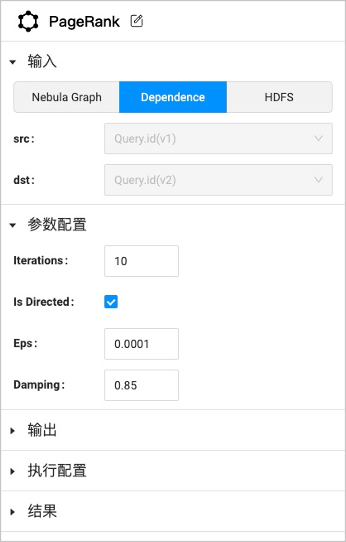
配置项 说明 PageRank 单击 可以修改组件名称,方别识别。输入 支持三种数据源作为输入。NebulaGraph 可以选择图空间和对应的边类型;Dependence 会根据锚点的连接情况自动识别;HDFS可以选择 HDFS 和数据源文件的相对路径。 参数配置 设置图算法特有的参数。不同算法的参数不同,部分参数可以从任意上游组件获取,此时锚点显示为黄色。 输出 显示图计算结果的列名,无法修改。 执行配置 机器数量表示将要执行算法的机器数量。
进程数量表示将要执行算法的总进程数,会根据机器数量平均分配到各个机器。
线程数量表示每个进程会启动多少个线程。结果 设置结果的保存位置。可以保存在 HDFS 或 NebulaGraph 中。
保存为 HDFS 时只需要选择 HDFS ,保存路径无需修改,会根据作业和任务 ID 自动生成。
保存为 NebulaGraph 时,需要预先在相应图空间中创建 Tag 用于保存结果。Tag 的属性说明请参见算法简介。
部分算法只支持保存在 HDFS 上。 -
在画布左上角自动生成的工作流名称旁单击
修改工作流名称,然后在画布右上角单击运行,会自动跳转至作业页面显示作业进度,耐心等待作业完成即可查看结果。详情参见作业管理。Note
单击运行时,会自动进行保存,如果不执行图计算,仅仅修改,修改完成后请单击
 进行保存,或者单击
进行保存,或者单击 另存为新的工作流。
另存为新的工作流。
常见问题¶
如何删除组件?¶
单击鼠标左键选择要删除的组件,单击Backspace即可删除该组件。
最后更新:
October 20, 2022