相关技术¶
本节主要介绍两个和分布式图数据库关系密切的领域,数据库方面和图技术方面。
数据库方面¶
关系型数据库¶
关系型数据库,是指采用了关系模型来组织数据的数据库。关系模型为二维表格模型,一个关系型数据库就是由二维表及其之间的联系所组成的一个数据组织。说到关系型数据库,大多数人都会想到 MySQL。MySQL 是目前最流行的数据库管理系统之一,支持使用最常见的结构化查询语言(SQL)进行数据库操作,并以表格、行、列的形式存储数据。这种存储数据的方法源自埃德加·科德(Edgar Frank Codd)于 1970 年提出的关系型数据模型。
在关系型数据库中,可以为待存储的每种类型的数据创建一个表。例如,球员表用来存储所有的球员信息,球队表用来存储球队信息等。SQL 表中的每行数据都必须包含一个主键(primary key)。主键是该行数据的唯一标识符。一般地,主键作为字段 ID 都是随行数自增的。关系型数据库自问世以来一直为计算机行业提供着非常好的服务,并将未来很长的时间内继续服务下去。
如果你用过 Excel、WPS 或其他类似的应用,你就会大概了解到关系数据库是如何工作的。首先设置好列,然后在对应的列下添加行数据。你可以对某一列数据进行求平均值或其他聚合操作,这与在关系型数据库 MySQL 中求平均值的操作类似。而 EXcel 中的数据透视表则相当于在关系型数据库 MySQL 中使用聚合函数和 CASE 语句对数据进行查询。一个 EXcel 文件可以有多张表,一张表就相当于 MySQL 的一张表。一个 EXcel 文件则类似于一个 MySQL 数据库。
关系型数据库中的关系¶
与图数据库不同,关系型数据库(或 SQL 型的数据库)中的边也是作为实体存储在专门的边表中的。先创建两个表,球员(player)和球队(team),然后再创建表 player_team 作为边表。边表通常由相关的表 join 而成。例如,此处的边表 player_team 就由球员表和球队表 join 而成。

这种存储边的方式在关联小型数据集时问题并不大,但是当关系型数据库中的关系太多时,问题就出现了。事实上,关系型数据库是非常“反关系的”。具体来说,当你只想查询一个球员的队友时,你必须对表中的所有数据进行 join 操作,然后再过滤掉你不需要的所有数据,当你的数据集达到一定规模时,这将给关系型数据库带来巨大压力。如果你想关联多张不同的表,可能在 join 爆炸(join bombs)前系统就已经无法响应了。
关系型数据库起源¶
上文提到,关系型数据模型最早是由 IBM 的工程师埃德加·科德(Edgar Frank Codd)于 1970 年提出的。科德写了几篇数据库管理系统方面的论文,论述了关系型数据模型的潜力。关系型数据模型不依赖于数据链接列表(网状数据或层级数据),而是更多依赖于数据集。他使用元组演算(tuple calculus)的数学方法论证了这些数据集能够完成与导航数据库管理系统相同的任务。唯一的要求是,关系型数据模型需要一种合适的查询语言,以保证数据库的一致性要求。这就为后来声明型的结构化查询语言(SQL)提供了灵感来源。IBM 的 R 系统是关系型数据模型的最早使用者之一。然而,由前 IBM 员工拉里·埃里森创办的名叫软件开发实验室的小公司在市场上击败了 IBM。该公司的产品就是后来为我们熟知的 Oracle。
由于“关系数据库”在当时是一个比较时髦的词汇,因此许多数据库供应商都喜欢在其产品名称中使用这个词汇,尽管他们的产品实际上并不是关系型的。为了防止这种情况并减少关系型数据模型的错误使用,科德提出了著名科德 12 定律(Codd's 12 rules)。所有关系型数据系统都必须遵循科德 12 定律。
NoSQL 数据库¶
图数据库并不是可以克服关系型数据库缺点的唯一替代方案。现在市面上还有很多非关系型数据库的产品,这些产品都可以叫做 NoSQL。NoSQL 一词最早于上世纪 90 年代末提出,可以解释为“非 SQL” 或“不仅是 SQL”,具体解释要根据语境判断。为便于理解,这里 NoSQL 可以解释成 “非关系型数据库”。不同于关系型数据库,NoSQL 数据库提供的数据存储、检索机制并不是基于表关系建模的。 NoSQL 数据库可以分为四类:
- 键值存储(key-value stores)
- 列式存储(column-family stores)
- 文件存储(document stores)
- 图数据库(graph databases)
下面将分别介绍这四类数据库。
键值存储¶
键值存储,顾名思义,就是使用键值对存储数据的数据库。不同于关系型数据库,键值存储是没有表和列的。如果一定要做类比,键值数据库本身就像一张有很多列(也就是键)的大表。在键值存储数据库中,数据(即键值对中的值)都是通过键来存储和查询的,通常用哈希列表来实现。这比传统的 SQL 数据库要简单得多,而且对于某些 web 应用来说,这就足够了。
键值模型对于 IT 系统来说优势在于简单、易部署。多数情况下,这种存储方式对非关联的数据很适用。如是只是存储数据而无需查询的话,使用这种存储方法就没有问题。但是如果 DBA 只对部分值进行查询或更新的时候,键值模型就显得效率低下了。常见的键值存储数据库有:Redis、Voldemort、Oracle BDB。
列式存储¶
NoSQL 数据库的列式存储与 NoSQL 数据库的键值存储有许多相似之处,因为列式存储仍然在使用键进行存储和检索。区别在于列式存储数据库中,列是最小的存储单元,每一列均由键、值以及用于版本控制和冲突解决的时间戳组成。这在分布式扩展时特别有用,因为在数据库更新时,可以使用时间戳定位过期数据。由于列式存储良好的扩展性,因此适用于非常大的数据集。常见的列式存储数据库有:HBase、Cassandra、HadoopDB 等。
文档存储¶
准确来说,NoSQL 数据库文档存储实际上也是基于键值的数据库,只不过对功能做了增强。数据仍然以键值的形式存储,但是文档存储中的值是结构化的文档,而不仅仅是一个字符串或单个值。也就是说,由于信息结构的增加,文档存储能够执行更优化的查询,并且使数据检索更加容易。因此,文档存储特别适合存储、索引并管理面向文档的数据或者类似的半结构化数据。
从技术上讲,作为一个半结构化的信息单元,文档存储中的文档可以是任何形式可用的文档,包括 XML、JOSN、YAML 等,这取决于数据库供应商的设计。 比如,JSON 就是一种常见的选择。虽然 JSON 不是结构化数据的最佳选择,但是 JSON 型的数据在前端和后端应用中都可以使用。常见的文档存储数据库有:MongoDB、CouchDB、Terrastore 等。
图存储¶
最后一类 NoSQL 数据库是图数据库。本书重点讨论的 NebulaGraph 也是一种图数据库。虽然同为 NoSQL 型数据库,但是图数据库与上述 NoSQL 数据库有本质上的差异。图数据库以点、边、属性的形式存储数据。其优点在于灵活性高,支持复杂的图形算法,可用于构建复杂的关系图谱。我们将在随后的章节中详细讨论图数据库。不过在本章中,你只要知道图数据库是一种 NoSQL 类型的数据库就可以了。常见的图数据库有:NebulaGraph、Neo4j、OrientDB 等。
图技术方面¶
来看一张 2020 年的图技术全景1

和图有关联的技术有很多,可以大致分为这么几类:
- 基础设施:包括图数据库、图计算(处理)引擎、图深度学习、云服务等。
- 应用:包括可视化、知识图谱、反诈骗、网络安全、社交网络等。
- 开发工具:包括图查询语言、建模工具、开发框架和库。
- 电子书籍2和会议等。
图语言¶
在上一节中,我们介绍了图语言的历史。在这一节中,我们对图语言的功能做一个分类:
- 近邻查询:查询给定点或者边的邻边、邻点,或者是 K 跳的近邻。
- 图模式匹配(Pattern matching):找到一个/所有的子图,满足给定的图模式;这个问题非常接近于"子图同构映射(subgraph isomorphism)"——虽然两个看上去不同的图,但其实是一模一样的3。
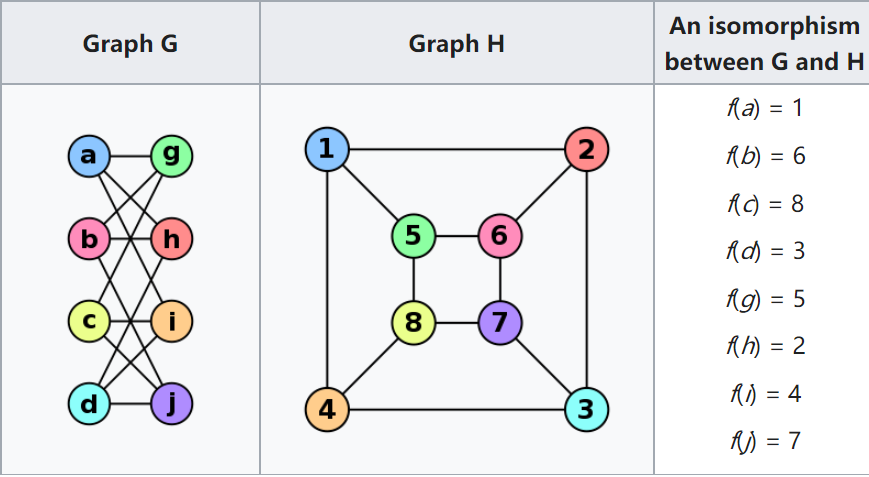
- 可达性(连通性)问题:最常见的可达性问题就是最短路径问题。泛化一些,这类问题通常用正则路径(Regular Path Query)的方式来描述——一系列联通的点组构成了一条路径,而该路径需要满足某种正则表达。
- 分析型问题:通常与一些汇聚型算子相关(平均值、count、最大值、点的出入度),或者度量所有两两点之间的距离、某节点与其他节点之间的互动程度(介数中心性)等。
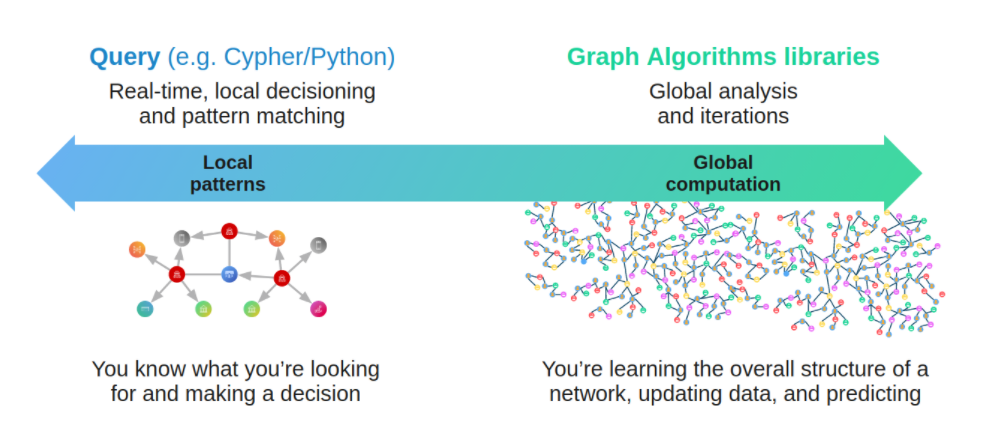
图数据库(Graph Database)与图处理(Graph processing)系统¶
一个图系统通常会涉及到复杂的数据流水线4,从数据源(左边)到处理输出(右边),会经过多个数据加工处理环节和系统;大的模块可以分为 ETL模块,图数据库系统(Graph OLTP),图处理系统(Graph OLAP),基于图引擎的应用系统(BI、知识图谱等)。
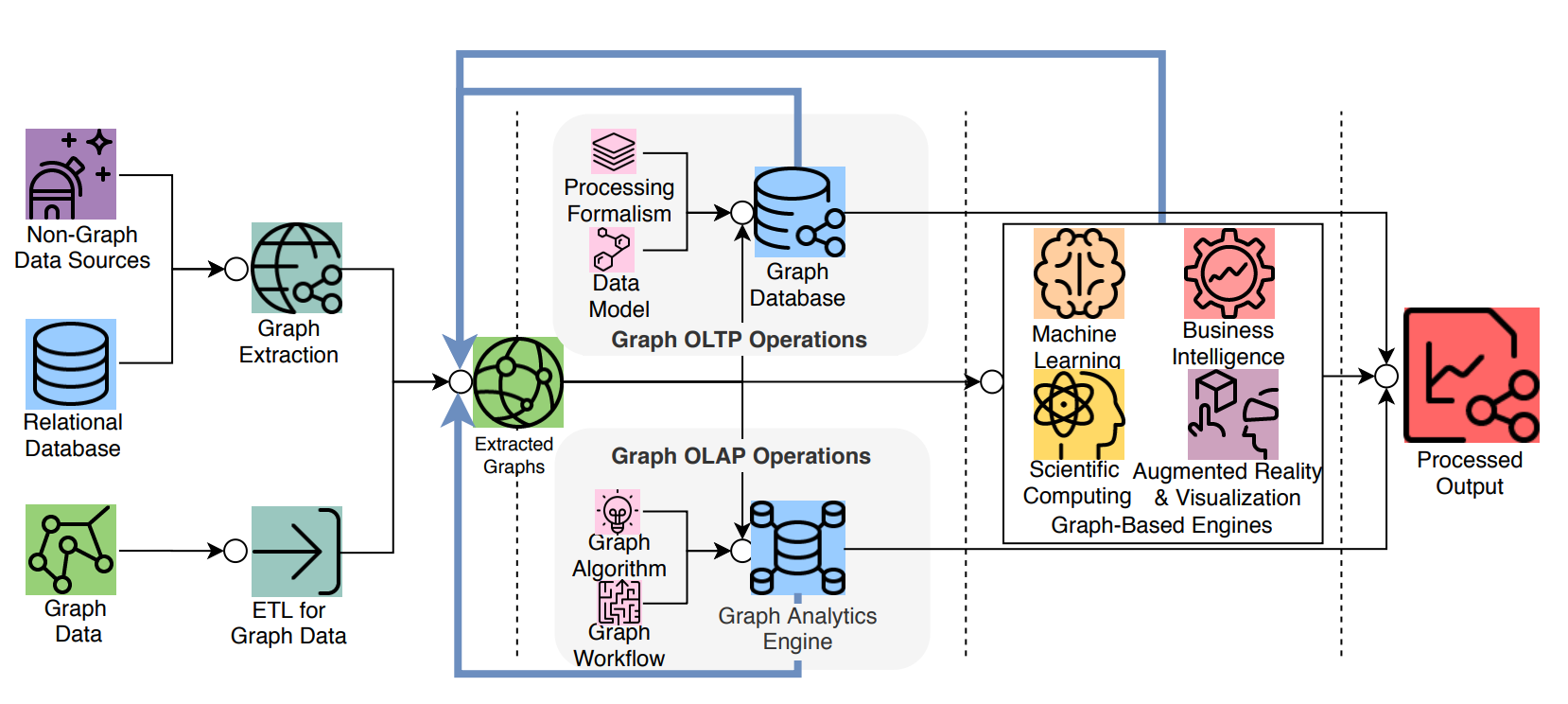
虽然这两类系统都是与图数据和图技术相关的系统,也处理类似的目标,但是他们有着不同的起源和特长(及弱点):
- (在线)图数据库目标是图的持久化存储管理、高效的子图操作。硬盘(及网络)是目标运行设备,物理/逻辑数据映射,数据完整性和(故障)一致性是主要目标。每一个请求通常只会涉及到全图的一小部分,通常可以在一台服务器上完成;单个请求时延通常在毫秒到秒级别,请求并发量通常在几千到几十万。早期的 Neo4j 是图数据库领域的起源之一。
- (离线)图处理系统目标是全图的大批量、并行、迭代、处理与分析,内存(及网络)是目标运行设备。每一个请求会涉及到所有的图节点,需要所有的服务器参与完成;单个请求的时延通常在分钟到小时(天),请求并发量通常为个位数。Google 的 Pregel5 是图处理系统的典型起源代表,它的点中心编程抽象与BSP的运行模式构成的编程范式,相比之前 Hadoop Map-Reduce 是更为图友好的 API 抽象。
图的分片方式¶
对于一个大规模的图数据来说,是很难存放在单个服务器的内存中的,即使仅仅存放图结构本身也不够。而且通过增加单服务器的能力,其成本价格通常成指数级别上升。 此外,随着数据量的增加,例如到达千亿级别的时候,已经超过了市面上所有商用服务器的容量能力。
与此对应的,另外一个经常使用的方案,是对数据进行分片,并将每个分片放置在不同的服务器上(并进行冗余备份),以此来增加可靠性和性能。对于一些 NoSQL 型的系统,例如 key-value 或者文档型的系统来说,这个分片方式是比较直观和自然的;通常可以根据 key 或者 docID,来将每个记录或者数据单元(key-value, doc)放在不同的服务器上。
但是图这种数据结构的分片通常不那么直观,这是因为通常图是“全联通”的,每个点通常只要6跳就可以联通到其他任何节点; 而理论上早已证明图的划分问题是 NP 的。 与此同时,当把整个图数据分散到多个服务器时,跨服务器的网络访问时延10倍于同一个服务器内部的硬件(内存)访问时间;因此对于一些深度优先遍历的场景,会发生大量的跨网络访问,导致整体时延极高。
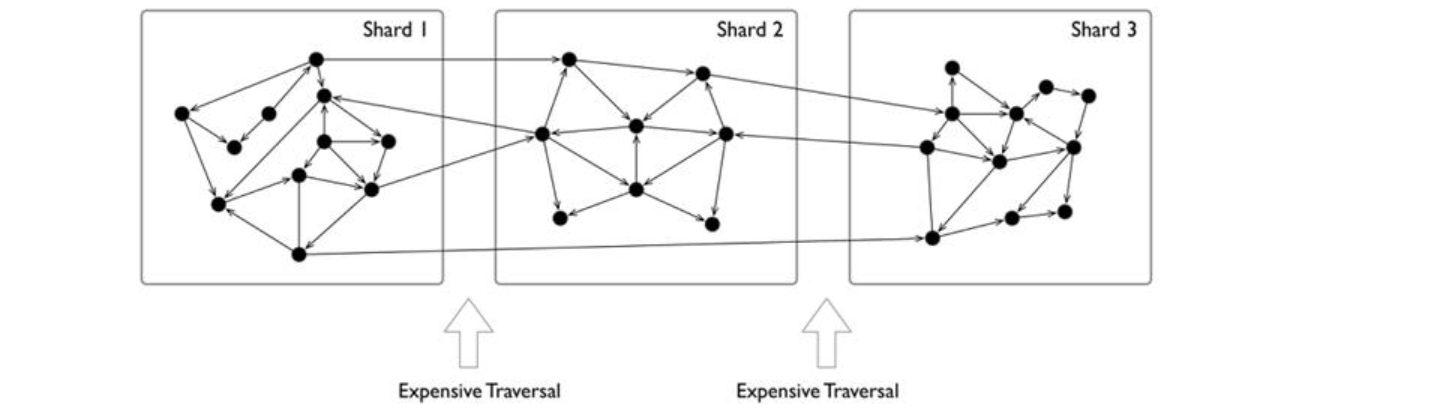
另一方面,通常图有着明显的幂律分布;少量节点的邻边稠密程度远大于平均的节点,虽然处理这些节点通常可以在同一台服务器内,减少了跨网络访问,但这也意味着这些服务器压力会远大于平均。
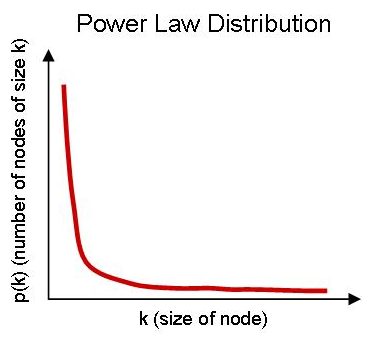
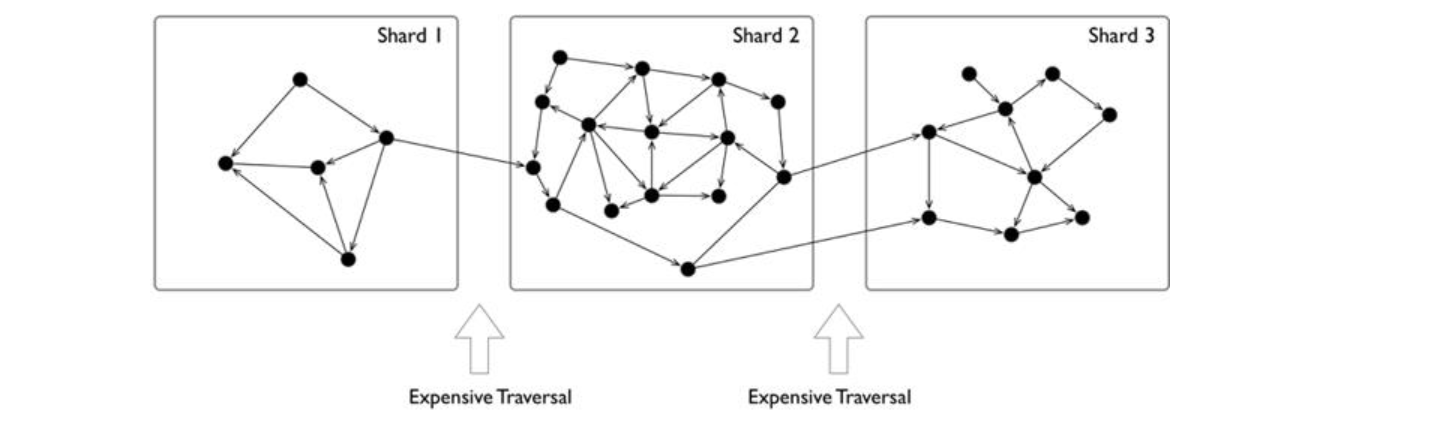
因此,常见的图分片(Sharding)方式有几类:
- 偏应用层面的分片:应用层感知并控制每个点和边应该落在哪个分片上,一般来说可以根据点和边的类型(比如业务意义来人为)判断。将一组相同类型的点放在一个分片,另一组相同类型的点放在另一个分片。当然,为了高可靠,分片本身还可以做多副本。在应用使用时,从各个分片取回所要的点和边,然后在偏应用侧(或者某个代理服务器端),将取回的数据拼装成最终的结果。其典型代表是 Neo4j 4.x 的 Fabric。
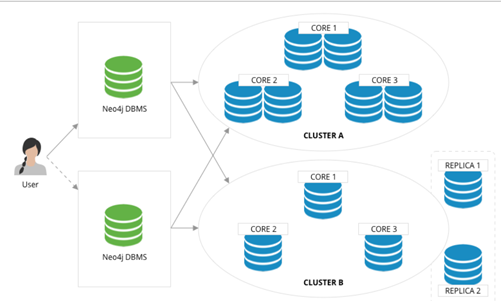
- 使用分布式的缓存层:在硬盘之上增加内存缓存层,并对重要的部分分片和数据(例如图结构)进行缓存,并预热这部分缓存。
- 增加(只读)副本或视图 (View):为部分图分片增加只读的副本或者建立一个视图,将较重的读请求负载通过这些分片服务器承担。
- 进行细颗粒度的图划分:例如将点和边组成多个小分片(Partition),而不是一台服务器一个大分片(Sharding),再将关联性较强的 Partition 尽量放置在同一个服务器上8。
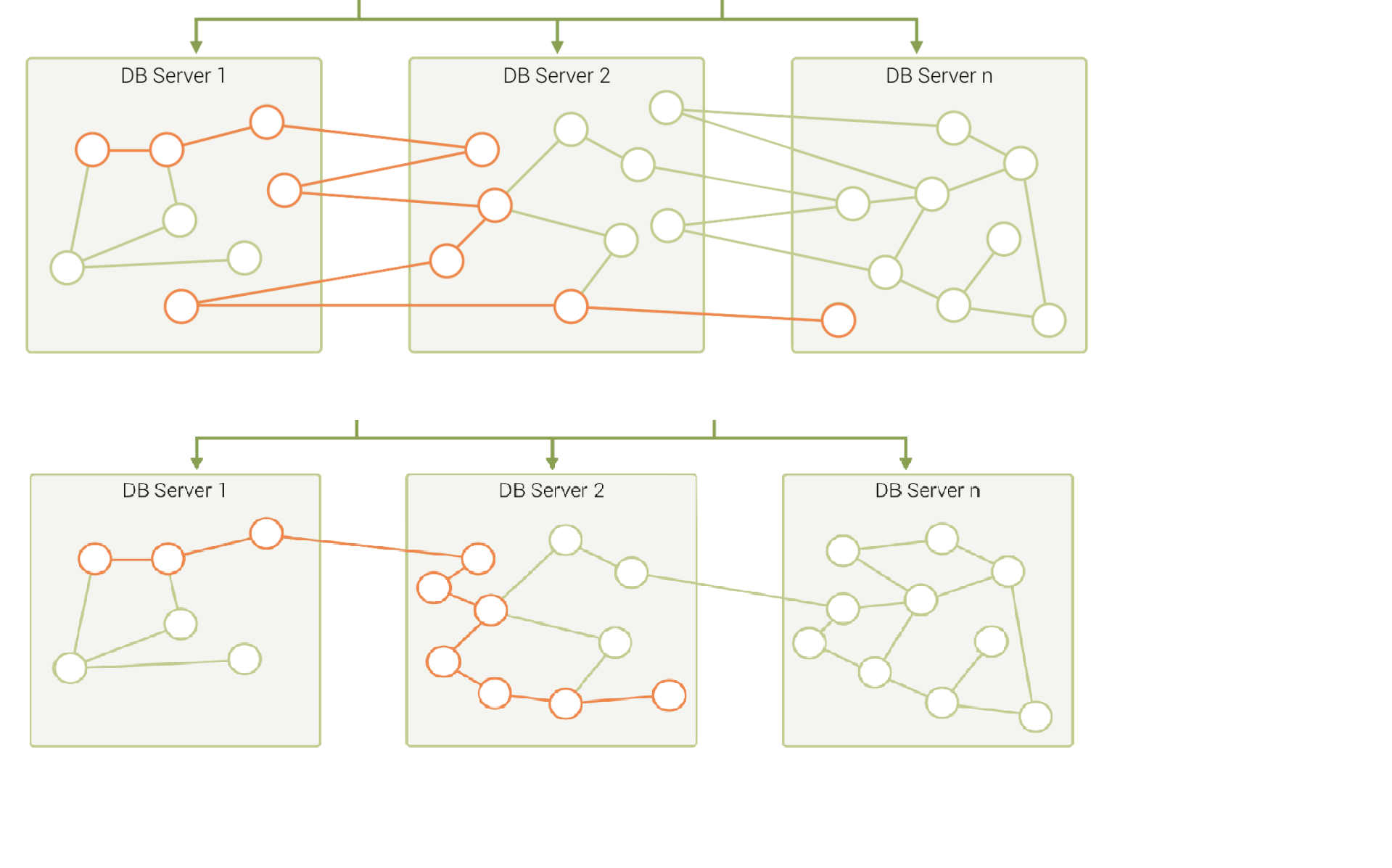
具体工程实践时,也会混合使用上述几种方式。通常,离线的图处理系统会通过一个ETL过程,将图进行一定程度的预处理以提高局部性;而在线图数据库系统通常会选择周期性的数据再平衡过程来提高数据局部性。
一些技术上的挑战¶
在文献9中,对于无处不在的大图和挑战做了详尽的调研,下面是其列出的十大图技术挑战:
- 可扩展性(软件可以处理更大的图规模): 包括大图的加载、更新、图计算和图遍历,触发器,超级节点;
- 可视化:可定制布局,大图的渲染,多层次展示,动态(更新)的展示
- 查询语言和编程 API:包括语言表达能力、标准兼容性、与现有系统的兼容性;子查询的设计和跨多图之间的关联查询
- 更快的图(及机器学习)算法
- 易用性(配置和使用)
- 性能指标与测试
- 更通用的图技术软件(例如,处理离线、在线、流式的计算)
- 图清洗(ETL)
- Debug 调试与测试
一些开源的单机图工具¶
对于图数据库通常会有一个误解,只要涉及到图结构的数据存取就需要存放在图数据库中,这是一种很大的浪费。
这就像也许你只需要一个 SQLite,却用了一个 Oracle。
当数据量并不大时,通常单机内存可以放下,例如数据量几千万的点边关系,使用一些单机的开源工具也可以取得很好的效果。
Note
下面是一些推荐的单机图库,也可以集成在你的应用程序里面。
- JGraphT10: 一个知名的开源 Java 图论库(library),其实现了相当多的高效图算法。
- JUNG11是BSD许可下用Java编写的开源图建模和可视化框架。该框架内置了许多布局算法,以及诸如图聚类和节点中心性度量之类的分析算法。
- igraph12: 一个轻量且功能强大的 Library, 支持R、python、C
- NetworkX13: 数据科学家做图论分析第一选择, python。
- Cytoscape14: 功能强大的可视化开源图分析工具。
- Gephi15: 功能强大的可视化开源图分析工具。
- arrows.app16: 非常简单的脑图工具,用于可视化生成 Cypher 语句.
一些行业数据集和 Benchmark¶
LDBC¶
关联数据基准委员会(LDBC17,Linked Data Benchmark Council)是由Oracle、Intel等软硬件巨头和主流图数据库厂商Neo4j和TigerGraph等组成的非赢利机构,是图的基准指南制定者与测试结果发布机构,在行业内有着很高的影响力。
社交网络基准测试(SNB,Social Network Benchmark)是由关联数据基准委员会(LDBC)开发的面向图数据库的基准测试(Benchmark)之一,分为交互式查询(Interactive)和商业智能(BI)两个场景。其作用类似于 TPC-C, TPC-H 等测试在 SQL 型数据库中的功能,可以帮助用户比较多种图数据库产品的功能、性能、容量。
SNB 数据集模拟一个社交网络的人、发帖之间的关系,考虑了社交网络的分布属性、人的活跃度等等社交信息。
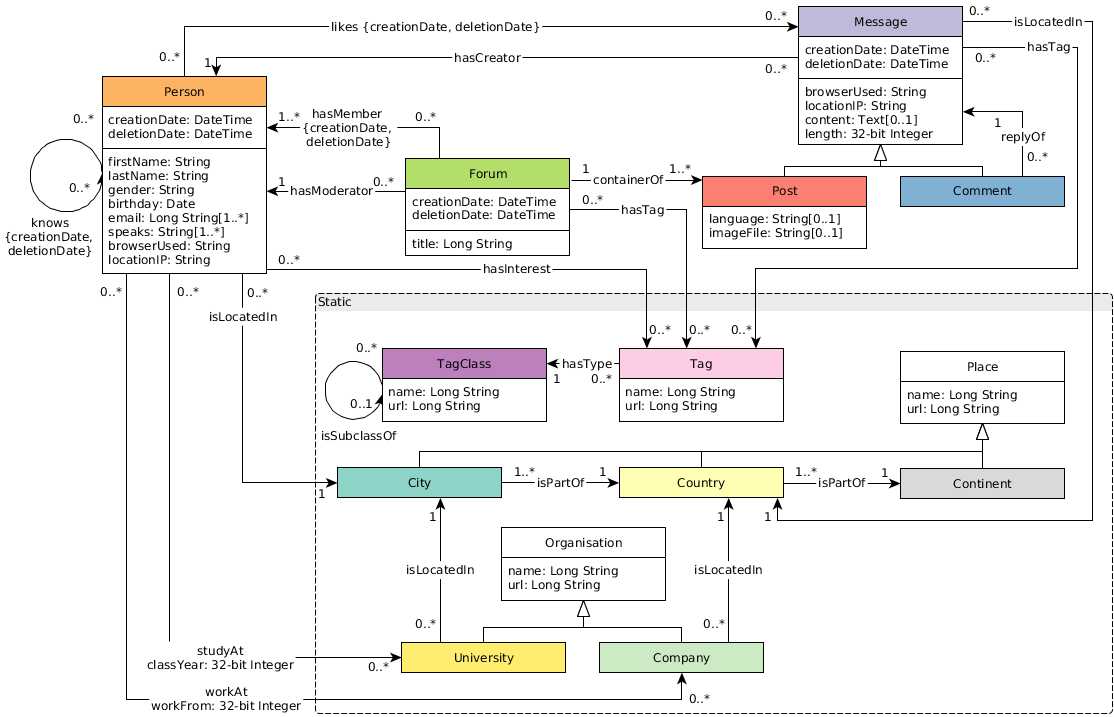
其标准数据量从 0.1 GB (scale factor 0.1) 到 1000 GB (sf1000),也可以生成 10 TB,100 TB等更大的数据集;其点、边数量如下表。

一些趋势¶
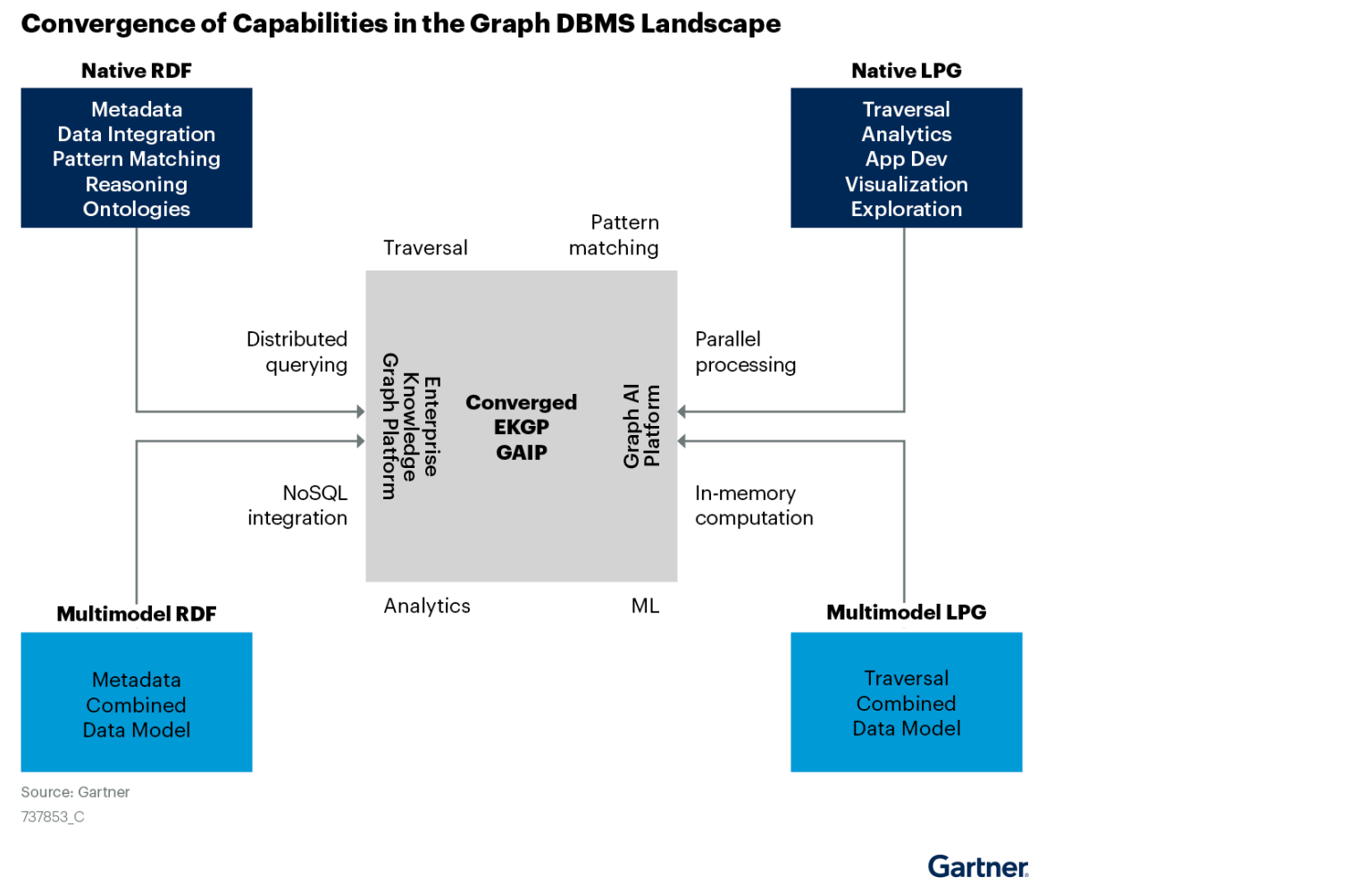
虽然图的各种技术起源和目标并不相同,但在相互借鉴和融合¶
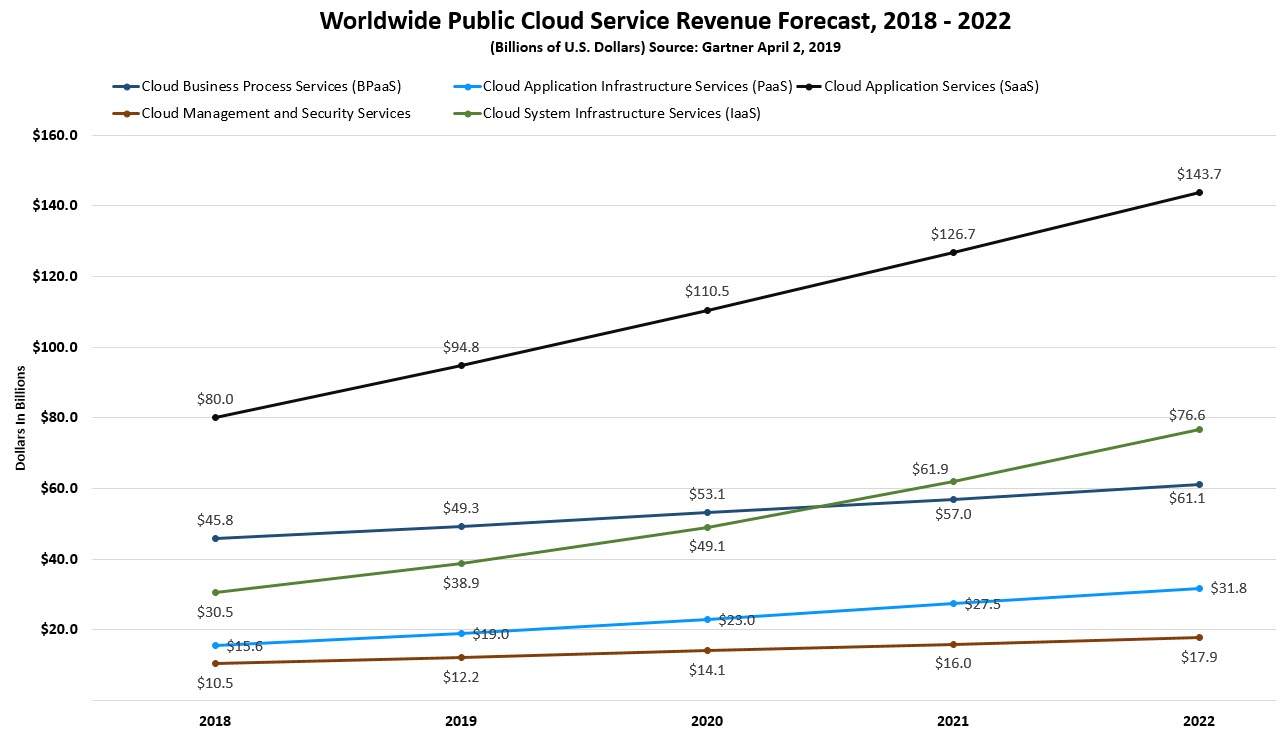
上云的趋势在加速,对于弹性能力提出更高要求¶
根据 Gartner 的预计,云服务一直保持较快的增速和渗透率18。大量的商业软件,正在从 10 年前完全私有本地逐步转向基于云服务的商业模式。 云服务的一大优点是其提供了近乎无限的弹性能力;这也要求各种基于云基础设施的软件必须有更好的快速弹性扩缩容能力。
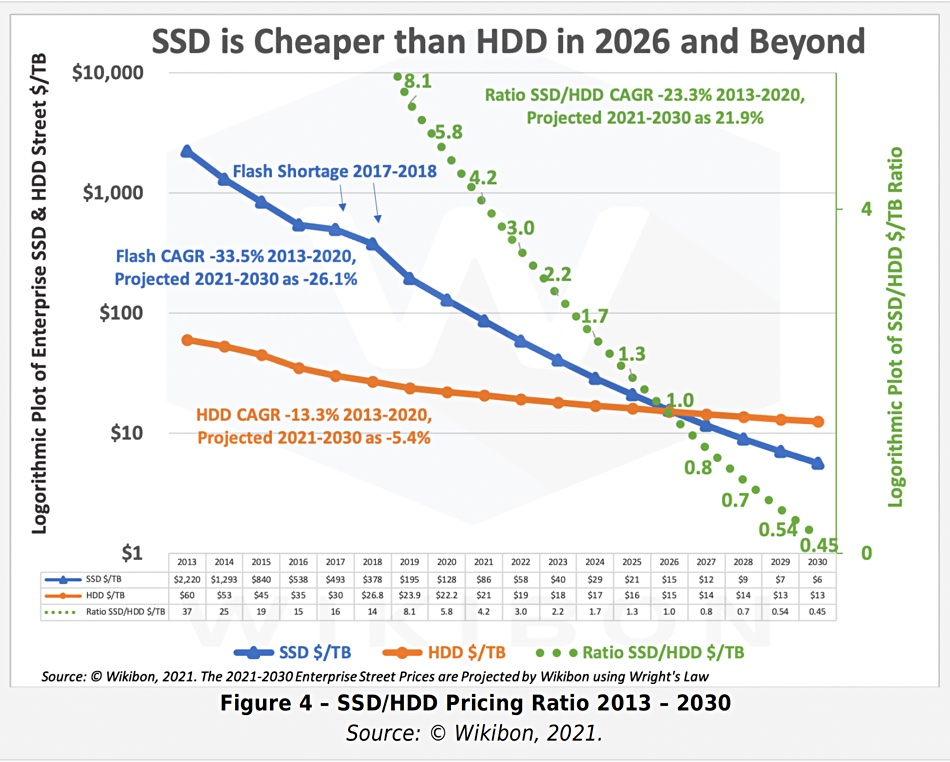
硬件趋势,SSD 将成为主流的持久化设备¶
硬件决定了软件的架构——从发现摩尔定律的 50 年代到进入多核的 00 年代,硬件发展趋势和速度一直深刻的决定了软件的架构。数据库类系统大多围绕“硬盘+内存”设计,高性能计算型系统大多围绕“内存 + CPU”设计,分布式系统面对千兆、万兆和 RDMA 网卡的设计也完全不同。
图基于拓扑的遍历有着极其明显的随机访问特点,因此大多数早期图数据库系统都采用了“大内存 + HDD” 的架构————通过设计常驻在内存中的一些数据结构(例如B+树、Hash表等),在内存中实现随机访问目的,以优化图的拓扑遍历,再将这些随机访问转换成 HDD 所适合的顺序读写。整套软件的架构(包括存储和计算层)都必须基于和围绕这样的 IO 流程来展开。随着 SSD 价格的快速下降19,SSD 正在替代 HDD 成为持久化设备的主流。SSD 随机访问友好、IO 队列深、按块存取的特点与 HDD 高度顺序、随机时延极高、磁道易损坏的访问特点有着明显的不同。全部的软件架构也需要重新设计,这成为沉重的历史技术负担。
-
https://graphaware.com/graphaware/2020/02/17/graph-technology-landscape-2020.html ↩
-
学习目的(非商业用途)可以联系[作者]((mailto:min.wu@vesoft.com)获取电子版。 ↩
-
https://en.wikipedia.org/wiki/Graph_isomorphism ↩
-
The Future is Big Graphs! A Community View on Graph Processing Systems. https://arxiv.org/abs/2012.06171 ↩
-
G. Malewicz, M. H. Austern, A. J. Bik, J. C. Dehnert, I. Horn, N. Leiser, and G. Czajkowski. Pregel: a system for large-scale graph processing. In Proceedings of the International Conference on Management of data (SIGMOD), pages 135–146, New York, NY, USA, 2010. ACM ↩
-
https://neo4j.com/graphacademy/training-iga-40/02-iga-40-overview-of-graph-algorithms/ ↩
-
https://livebook.manning.com/book/graph-powered-machine-learning/welcome/v-8/ ↩
-
https://www.arangodb.com/learn/graphs/using-smartgraphs-arangodb/ ↩
-
https://arxiv.org/abs/1709.03188 ↩
-
https://jgrapht.org/ ↩
-
https://github.com/jrtom/jung ↩
-
https://igraph.org/ ↩
-
https://networkx.org/ ↩
-
https://cytoscape.org/ ↩
-
https://gephi.org/ ↩
-
https://arrows.app/ ↩
-
https://github.com/ldbc/ldbc_snb_docs ↩
-
https://cloudcomputing-news.net/news/2019/apr/15/public-cloud-soaring-to-331b-by-2022-according-to-gartner/ ↩
-
https://blocksandfiles.com/2021/01/25/wikibon-ssds-vs-hard-drives-wrights-law/ ↩