常见问题 FAQ¶
本文列出了使用 NebulaGraph 3.6.0 时可能遇到的常见问题,用户可以使用文档中心或者浏览器的搜索功能查找相应问题。
如果按照文中的建议无法解决问题,请到 NebulaGraph 论坛 提问或提交 GitHub issue。
关于本手册¶
为什么手册示例和系统行为不一致?¶
NebulaGraph 一直在持续开发,功能或操作的行为可能会有变化,如果发现不一致,请提交 issue 通知 NebulaGraph 团队。
Note
如果发现本文档中的错误:
- 用户可以点击页面顶部右上角的"铅笔"图标进入编辑页面。
- 使用 Markdown 修改文档。完成后点击页面底部的 "Commit changes",这会触发一个 GitHub pull request。
- 完成 CLA 签署,并且至少 2 位 reviewer 审核通过即可合并。
关于历史兼容性¶
Compatibility
NebulaGraph 3.6.0 与 历史版本 (包括 NebulaGraph 1.x 和 2.x) 的数据格式、客户端通信协议均双向不兼容。 使用老版本客户端连接新版本服务端,会导致服务进程退出。 数据格式升级参见升级 NebulaGraph 历史版本至当前版本。 客户端与工具均需要下载对应版本。
关于执行报错¶
如何处理错误信息-1005:GraphMemoryExceeded: (-2600)¶
这个错误是由 Memory Tracker 发出的,它在观察到内存使用超过了设定阈值时发出警报。这个机制可以帮助避免服务进程被系统的 OOM(Out of Memory)killer 终止。解决步骤:
-
检查内存使用情况:首先,你需要查看命令执行过程中的内存用量。如果内存使用量确实很高,那么这个错误可能是预期中的情况。
-
检查 Memory Tracker 的配置:如果内存使用量并不高,检查 Memory Tracker 的相关配置。这包括
memory_tracker_untracked_reserved_memory_mb(未被跟踪的预留内存量,单位为 MB),memory_tracker_limit_ratio(内存限制比例),以及memory_purge_enabled(是否启用内存清理)。关于 Memory Tracker 的配置,参见 memory tracker 配置。 -
优化配置:根据实际情况,调整这些配置。例如,如果可用内存限制过低,可以调高
memory_tracker_limit_ratio的值。
如何处理错误信息SemanticError: Missing yield clause¶
从 NebulaGraph 3.0.0 开始,查询语句LOOKUP、GO、FETCH必须用YIELD子句指定输出结果。详情请参见YIELD。
如何处理错误信息Host not enough!¶
从 3.0.0 版本开始,在配置文件中添加的 Storage 节点无法直接读写,配置文件的作用仅仅是将 Storage 节点注册至 Meta 服务中。必须使用ADD HOSTS命令后,才能正常读写 Storage 节点。详情参见管理 Storage 主机。
如何处理错误信息To get the property of the vertex in 'v.age', should use the format 'var.tag.prop'¶
从 3.0.0 版本开始,pattern支持同时匹配多个 Tag,所以返回属性时,需要额外指定 Tag 名称。即从RETURN 变量名.属性名改为RETURN 变量名.Tag名.属性名。
如何处理错误信息 Used memory hits the high watermark(0.800000) of total system memory.¶
报错原因: NebulaGraph 的system_memory_high_watermark_ratio参数指定了内存高水位报警机制的触发阈值,默认为0.8。系统内存占用率高于该值会触发报警机制,NebulaGraph 会停止接受查询。
解决方案:
- 清理系统内存,使其降低到阈值以下。
- 修改 Graph 配置。在所有 Graph 服务器的配置文件中增加
system_memory_high_watermark_ratio参数,为其设置一个大于0.8的值,例如0.9。
需要注意的是system_memory_high_watermark_ratio参数已被弃用。建议用户使用 Memory Tracker 功能来限制NebulaGraph的内存使用量。详情请参见 Graph 服务的 memory tracker 配置和 Storage 服务的 memory tracker 配置。
如何处理错误信息Storage Error E_RPC_FAILURE¶
报错原因通常为 Graph 服务向 Storage 服务请求了过多的数据,导致 Storage 服务超时。请尝试以下解决方案:
- 修改配置文件:在
nebula-graphd.conf文件中修改--storage_client_timeout_ms参数的值,以增加 Storage client 的连接超时时间。该值的单位为毫秒(ms)。例如,设置--storage_client_timeout_ms=60000。如果nebula-graphd.conf文件中未配置该参数,请手动增加。提示:请在配置文件开头添加--local_config=true再重启服务。 - 优化查询语句:减少全库扫描型的查询,无论是否用
LIMIT限制了返回结果的数量;用 GO 语句改写 MATCH 语句(前者有优化,后者无优化)。 - 检查 Storaged 是否发生过 OOM。(
dmesg |grep nebula)。 - 为 Storage 服务器提供性能更好的 SSD 或者内存。
- 重试请求。
如何处理错误信息The leader has changed. Try again later¶
已知问题,通常需要重试 1-N 次 (N==partition 数量)。原因为 meta client 更新 leader 缓存需要 1-2 个心跳或者通过错误触发强制更新。
如果登录 NebulaGraph 时,出现该报错,可以考虑使用 df -h 查看磁盘空间,检查本地磁盘空间是否已满。
Schema not exist: xxx¶
查询时提示Schema not exist,请确认:
- Schema 中是否存在该 Tag 或 Edge type。
- Tag 或 Edge type 的名称是否为关键字,如果是关键字,请使用反引号(`)将它们括起来。详情请参见关键字。
编译 Exchange、Connectors、Algorithm 时无法下载 SNAPSHOT 包¶
现象:编译时提示Could not find artifact com.vesoft:client:jar:xxx-SNAPSHOT。
原因:本地 maven 没有配置用于下载 SNAPSHOT 的仓库。maven 中默认的 central 仓库用于存放正式发布版本,而不是开发版本(SNAPSHOT)。
解决方案:在 maven 的 setting.xml文件的profiles作用域内中增加以下配置:
<profile>
<activation>
<activeByDefault>true</activeByDefault>
</activation>
<repositories>
<repository>
<id>snapshots</id>
<url>https://oss.sonatype.org/content/repositories/snapshots/</url>
<snapshots>
<enabled>true</enabled>
</snapshots>
</repository>
</repositories>
</profile>
如何处理错误信息[ERROR (-1004)]: SyntaxError: syntax error near?¶
大部分情况下,查询语句需要有YIELD或RETURN,请检查查询语句是否包含。
如何处理错误信息can’t solve the start vids from the sentence¶
查询引擎需要知道从哪些 VID 开始图遍历。这些开始图遍历的 VID,或者通过用户指定,例如:
> GO FROM ${vids} ...
> MATCH (src) WHERE id(src) == ${vids}
# 开始图遍历的 VID 通过如上办法指定
或者通过一个属性索引来得到,例如:
# CREATE TAG INDEX IF NOT EXISTS i_player ON player(name(20));
# REBUILD TAG INDEX i_player;
> LOOKUP ON player WHERE player.name == "abc" | ... YIELD ...
> MATCH (src) WHERE src.name == "abc" ...
# 通过点属性 name 的索引,来得到 VID
否则,就会抛出这样一个异常 can’t solve the start vids from the sentence。
如何处理错误信息Wrong vertex id type: 1001¶
检查输入的 VID 类型是否是create space设置的INT64或FIXED_STRING(N)。详情请参见 create space。
如何处理错误信息The VID must be a 64-bit integer or a string fitting space vertex id length limit.¶
检查输入的 VID 是否超过限制长度。详情请参见 create space。
如何处理错误信息 edge conflict 或 vertex conflict¶
Storage 服务在毫秒级时间内多次收到插入或者更新同一点或边的请求时,可能返回该错误。请稍后重试。
如何处理错误信息 RPC failure in MetaClient: Connection refused¶
报错原因通常为 metad 服务状态异常,或是 metad 和 graphd 服务所在机器网络不通。请尝试以下解决方案:
- 在 metad 所在服务器查看下 metad 服务状态,如果服务状态异常,可以重新启动 metad 服务。
- 在报错服务器下使用
telnet meta-ip:port查看网络状态。
- 检查配置文件中的端口配置,如果端口号与连接时使用的不同,改用配置文件中的端口或者修改配置。
如何处理 nebula-graph.INFO 中错误日志 StorageClientBase.inl:214] Request to "x.x.x.x":9779 failed: N6apache6thrift9transport19TTransportExceptionE: Timed Out¶
报错原因可能是查询的数据量比较大,storaged 处理超时。请尝试以下解决方法:
- 导入数据时,手动 compaction,加速读的速度。
- 增加 Graph 服务与 Storage 服务的 RPC 连接超时时间,在
nebula-graphd.conf文件里面修改--storage_client_timeout_ms参数的值。该值的单位为毫秒(ms),默认值为 60000 毫秒。
如何处理 nebula-storaged.INFO 中错误日志 MetaClient.cpp:65] Heartbeat failed, status:Wrong cluster! 或者 nebula-metad.INFO 含有错误日志HBProcessor.cpp:54] Reject wrong cluster host "x.x.x.x":9771!¶
报错的原因可能是用户修改了 metad 的 ip 或者端口信息,或者 storage 之前加入过其他集群。请尝试以下解决方法:
用户到 storage 部署的机器所在的安装目录(默认安装目录为 /usr/local/nebula)下面将cluster.id文件删除,然后重启 storaged 服务。
如何处理报错信息Storage Error: More than one request trying to add/update/delete one edge/vertex at he same time.¶
上述报错表示当前版本不允许同时对一个点或者一条边进行并发操作。如出现此报错请重新执行操作命令。
如何处理错误信息 The maximum number of statements allowed has been exceeded 和 the maximum number of statements for Nebula is 512¶
这两个报错信息都是由于单条插入语句长度超过 max_allowed_statements 引起的,通过修改 nebula-graphd.conf 配置文件的 etc 目录下 --max_allowed_statements 参数项,能避免语句插入报错。
关于设计与功能¶
返回消息中 time spent 的含义是什么?¶
将命令SHOW SPACES返回的消息作为示例:
nebula> SHOW SPACES;
+--------------------+
| Name |
+--------------------+
| "basketballplayer" |
+--------------------+
Got 1 rows (time spent 1235/1934 us)
- 第一个数字
1235表示数据库本身执行该命令花费的时间,即查询引擎从客户端接收到一个查询,然后从存储服务器获取数据并执行一系列计算所花费的时间。
- 第二个数字
1934表示从客户端角度看所花费的时间,即从客户端发送请求、接收结果,然后在屏幕上显示结果所花费的时间。
为什么在正常连接 NebulaGraph 后,nebula-storaged进程的端口号一直显示红色?¶
nebula-storaged进程的端口号的红色闪烁状态是因为nebula-storaged在启动流程中会等待nebula-metad添加当前 Storage 服务,当前 Storage 服务收到 Ready 信号后才会正式启动服务。从 3.0.0 版本开始,Meta 服务无法直接读写在配置文件中添加的 Storage 服务,配置文件的作用仅仅是将 Storage 服务注册至 Meta 服务中。用户必须使用ADD HOSTS命令后,才能使 Meta 服务正常读写 Storage 服务。更多信息,参见管理 Storage 主机。
为什么 NebulaGraph 的返回结果每行之间没有横线分隔了?¶
这是 NebulaGraph Console 2.6.0 版本的变动造成的,不是 NebulaGraph 内核的变更,不影响返回数据本身的内容。
关于悬挂边¶
悬挂边 (Dangling edge) 是指一条边的起点或者终点在数据库中不存在。
NebulaGraph 3.6.0 的数据模型中,由于设计允许图中存在“悬挂边”; 没有 openCypher 中的 MERGE 语句。 对于悬挂边的保证完全依赖应用层面。 详见 INSERT VERTEX, DELETE VERTEX, INSERT EDGE, DELETE EDGE。
可以在CREATE SPACE时设置replica_factor为偶数(例如设置为 2)吗?¶
不要这样设置。
Storage 服务使用 Raft 协议(多数表决),为保证可用性,要求出故障的副本数量不能达到一半。
当机器数量为 1 时,replica_factor只能设置为1。
当机器数量足够时,如果replica_factor=2,当其中一个副本故障时,就会导致系统无法正常工作;如果replica_factor=4,只能有一个副本可以出现故障,这和replica_factor=3是一样。以此类推,所以replica_factor设置为奇数即可。
建议在生产环境中设置replica_factor=3,测试环境中设置replica_factor=1,不要使用偶数。
是否支持停止或者中断慢查询¶
支持。
详情请参见终止查询。
使用GO和MATCH执行相同语义的查询,查询结果为什么不同?¶
原因可能有以下几种:
GO查询到了悬挂边。
RETURN命令未指定排序方式。
- 触发了 Storage 服务中
max_edge_returned_per_vertex定义的稠密点截断限制。
-
路径的类型不同,导致查询结果可能会不同。
GO语句采用的是walk类型,遍历时点和边可以重复。
MATCH语句兼容 openCypher,采用的是trail类型,遍历时只有点可以重复,边不可以重复。
因路径类型不同导致查询结果不同的示例图和说明如下。
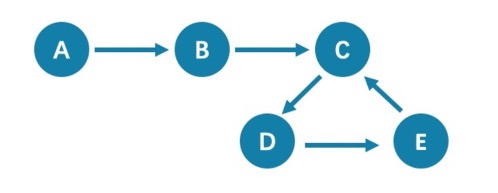
从点 A 开始查询距离 5 跳的点,都会查询到点 C(A->B->C->D->E->C),查询 6 跳的点时,GO语句会查询到点 D(A->B->C->D->E->C->D),因为边C->D可以重复查询,而MATCH语句查询为空,因为边不可以重复。
所以使用GO和MATCH执行相同语义的查询,可能会出现MATCH语句的查询结果比GO语句少。
关于路径的详细说明,请参见维基百科。
如何统计每种 Tag 有多少个点,每个 Edge type 有多少条边?¶
请参见 show-stats。
如何获取每种 Tag 的所有点,或者每种 Edge type 的所有边?¶
-
建立并重建索引。
> CREATE TAG INDEX IF NOT EXISTS i_player ON player(); > REBUILD TAG INDEX i_player; -
使用
LOOKUP或MATCH语句。例如:> LOOKUP ON player; > MATCH (n:player) RETURN n;
能不能用中文字符做标识符,比如图空间、Tag、Edge type、属性、索引的名称?¶
能,详情参见关键字和保留字。
获取指定点的出度(或者入度)?¶
一个点的“出度”是指从该点出发的“边”的条数。入度,是指指向该点的边的条数。
nebula > MATCH (s)-[e]->() WHERE id(s) == "given" RETURN count(e); #出度
nebula > MATCH (s)<-[e]-() WHERE id(s) == "given" RETURN count(e); #入度
因为没有对出度和入度的进行特殊处理(例如索引或者缓存),这是一个较慢的操作。特别当遇到超级节点时,可能会发生OOM。
是否有办法快速获取“所有”点的出度和入度?¶
没有直接命令。
可以使用 NebulaGraph Algorithm。
关于运维¶
运行日志文件过大时如何回收日志?¶
NebulaGraph使用 glog 打印日志,glog 没有日志回收的功能。用户可以通过定时任务或日志管理工具 logrotate 来管理运行日志。操作详情,参见回收日志。
如何查看 NebulaGraph 版本¶
服务运行时:nebula-console 中执行命令 SHOW HOSTS META,详见 SHOW HOSTS
服务未运行时:在安装路径的bin目录内,执行./<binary_name> --version命令,可以查看到 version 和 GitHub 上的 commit ID,例如:
$ ./nebula-graphd --version
-
Docker Compose 部署
查看 Docker Compose 部署的 NebulaGraph 版本,方式和编译安装类似,只是要先进入容器内部,示例命令如下:
docker exec -it nebula-docker-compose_graphd_1 bash cd bin/ ./nebula-graphd --version
-
RPM/DEB 包安装
执行
rpm -qa |grep nebula即可查看版本。
修改 Host 名称后,旧的 Host 一直显示 OFFLINE 怎么办?¶
OFFLINE 状态的 Host 将在一天后自动删除。
如何查看 dmp 文件?¶
dmp 文件是错误报告文件,详细记录了进程退出的信息,可以用操作系统自带的 gdb 工具查看。Coredump 文件默认保存在启动二进制的当前目录下(默认为/usr/local/nebula目录),在 NebulaGraph 服务 crash 时,系统会自动生成。
- 查看 Core 文件进程名字,pid 一般为数值。
$ file core.<pid> - 使用 gdb 调试。
$ gdb <process.name> core.<pid> - 查看文件内容。
例如:
$(gdb) bt
$ file core.1316027
core.1316027: ELF 64-bit LSB core file, x86-64, version 1 (SYSV), SVR4-style, from '/home/workspace/fork/nebula-debug/bin/nebula-metad --flagfile /home/k', real uid: 1008, effective uid: 1008, real gid: 1008, effective gid: 1008, execfn: '/home/workspace/fork/nebula-debug/bin/nebula-metad', platform: 'x86_64'
$ gdb /home/workspace/fork/nebula-debug/bin/nebula-metad core.1316027
$(gdb) bt
#0 0x00007f9de58fecf5 in __memcpy_ssse3_back () from /lib64/libc.so.6
#1 0x0000000000eb2299 in void std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >::_M_construct<char*>(char*, char*, std::forward_iterator_tag) ()
#2 0x0000000000ef71a7 in nebula::meta::cpp2::QueryDesc::QueryDesc(nebula::meta::cpp2::QueryDesc const&) ()
...
如果用户不清楚 dmp 打印出来的相关信息,可以将打印出来的内容,带上操作系统版本、硬件配置、Core文件产生前后的错误日志和可能导致错误的操作贴在 NebulaGraph 论坛上寻求帮助。
如何通过 systemctl 设置开机自动启动 NebulaGraph 服务?¶
-
执行
systemctl enable启动 metad、graphd 和 storaged 服务。[root]# systemctl enable nebula-metad.service Created symlink from /etc/systemd/system/multi-user.target.wants/nebula-metad.service to /usr/lib/systemd/system/nebula-metad.service. [root]# systemctl enable nebula-graphd.service Created symlink from /etc/systemd/system/multi-user.target.wants/nebula-graphd.service to /usr/lib/systemd/system/nebula-graphd.service. [root]# systemctl enable nebula-storaged.service Created symlink from /etc/systemd/system/multi-user.target.wants/nebula-storaged.service to /usr/lib/systemd/system/nebula-storaged.service. -
配置 metad、graphd 和 storaged 的 service 文件,设置服务自动拉起。
Caution
在配置service文件时需注意以下几点: - PIDFile、ExecStart、ExecReload、ExecStop 参数的路径需要与服务器上的一致。 - RestartSec 为重启前等待的时长(秒),可根据实际情况修改。 - (可选)StartLimitInterval 为无限次重启,默认是 10 秒内如果重启超过 5 次则不再重启,设置为 0 表示不限次数重启。 - (可选)LimitNOFILE 为服务最大文件打开数,默认为1024,可根据实际情况修改。
配置 metad 服务的 service 文件:
$ vi /usr/lib/systemd/system/nebula-metad.service [Unit] Description=Nebula Graph Metad Service After=network.target [Service ] Type=forking Restart=always RestartSec=15s PIDFile=/usr/local/nebula/pids/nebula-metad.pid ExecStart=/usr/local/nebula/scripts/nebula.service start metad ExecReload=/usr/local/nebula/scripts/nebula.service restart metad ExecStop=/usr/local/nebula/scripts/nebula.service stop metad PrivateTmp=true StartLimitInterval=0 LimitNOFILE=1024 [Install] WantedBy=multi-user.target配置 graphd 服务的 service 文件:
$ vi /usr/lib/systemd/system/nebula-graphd.service [Unit] Description=Nebula Graph Graphd Service After=network.target [Service] Type=forking Restart=always RestartSec=15s PIDFile=/usr/local/nebula/pids/nebula-graphd.pid ExecStart=/usr/local/nebula/scripts/nebula.service start graphd ExecReload=/usr/local/nebula/scripts/nebula.service restart graphd ExecStop=/usr/local/nebula/scripts/nebula.service stop graphd PrivateTmp=true StartLimitInterval=0 LimitNOFILE=1024 [Install] WantedBy=multi-user.target配置 storaged 服务的 service 文件:
$ vi /usr/lib/systemd/system/nebula-storaged.service [Unit] Description=Nebula Graph Storaged Service After=network.target [Service] Type=forking Restart=always RestartSec=15s PIDFile=/usr/local/nebula/pids/nebula-storaged.pid ExecStart=/usr/local/nebula/scripts/nebula.service start storaged ExecReload=/usr/local/nebula/scripts/nebula.service restart storaged ExecStop=/usr/local/nebula/scripts/nebula.service stop storaged PrivateTmp=true StartLimitInterval=0 LimitNOFILE=1024 [Install] WantedBy=multi-user.target -
reload 配置文件。
[root]# sudo systemctl daemon-reload -
重启服务。
$ systemctl restart nebula-metad.service $ systemctl restart nebula-graphd.service $ systemctl restart nebula-storaged.service
关于连接¶
防火墙中需要开放哪些端口?¶
如果没有修改过配置文件中预设的端口,请在防火墙中开放如下端口:
| 服务类型 | 端口 |
|---|---|
| Meta | 9559, 9560, 19559 |
| Graph | 9669, 19669 |
| Storage | 9777 ~ 9780, 19779 |
如果修改过配置文件中预设的端口,请找出实际使用的端口并在防火墙中开放它们。
更多端口信息,参见公司产品端口全集。
如何测试端口是否已开放?¶
用户可以使用如下 telnet 命令检查端口状态:
telnet <ip> <port>
Note
如果无法使用 telnet 命令,请先检查主机中是否安装并启动了 telnet。
示例:
// 如果端口已开放:
$ telnet 192.168.1.10 9669
Trying 192.168.1.10...
Connected to 192.168.1.10.
Escape character is '^]'.
// 如果端口未开放:
$ telnet 192.168.1.10 9777
Trying 192.168.1.10...
telnet: connect to address 192.168.1.10: Connection refused
会话数量达到max_sessions_per_ip_per_user所设值上限时怎么办?¶
当会话数量达到上限时,即超过max_sessions_per_ip_per_user所设值,在连接 NebulaGraph 的时候,会出现以下报错:
Fail to create a new session from connection pool, fail to authenticate, error: Create Session failed: Too many sessions created from 127.0.0.1 by user root. the threshold is 2. You can change it by modifying 'max_sessions_per_ip_per_user' in nebula-graphd.conf
用户可以通过以下三种方式解决问题:
- 执行
KILL SESSION命令,关闭不需要的 Session。详情参见终止会话。 - 在 Graph 服务的配置文件
nebula_graphd.conf中增大max_sessions_per_ip_per_user的值,增加可以创建的会话总数。重启 Graph 服务使配置生效。 - 在 Graph 服务的配置文件
nebula_graphd.conf中减小session_idle_timeout_secs参数的值,降低空闲会话的超时时间。重启 Graph 服务使配置生效。
关于扩容、缩容¶
Warning
集群扩缩容功能未正式在社区版中发布。以下涉及SUBMIT JOB BALANCE DATA REMOVE和SUBMIT JOB BALANCE DATA的操作在社区版中均为实验性功能,功能未稳定。如需使用,请先做好数据备份,并且在 Graph 配置文件中将enable_experimental_feature和enable_data_balance均设置为true。
如何增加或减少 Meta、Graph、Storage 节点的数量¶
-
NebulaGraph 3.6.0 未提供运维命令以实现自动扩缩容,但可参考以下步骤实现手动扩缩容:
-
Meta 的扩容和缩容: Meta 不支持自动扩缩容。
Note
用户可以使用脚本工具 迁移 Meta 服务,但是需要自行修改 Graph 服务和 Storage 服务的配置文件中的 Meta 设置。
- Graph 的缩容:将该 Graph 的 IP 从 client 的代码中移除,关闭该 Graph 进程。
- Graph 的扩容:在新机器上准备 Graph 二进制文件和配置文件,在配置文件中修改或增加已在运行的 Meta 地址,启动 Graph 进程。
-
Storage 的缩容:执行
SUBMIT JOB BALANCE DATA REMOVE <ip:port>和DROP HOSTS <ip:port>。完成后关闭 Storage 进程。Caution
- 执行该命令迁移指定 Storage 节点中的分片数据前,需要确保其他 Storage 节点数量足够以满足设置的副本数。例如,如果设置了副本数为 3,那么在执行该命令前,需要确保其他 Storage 节点数量大于等于 3。
- 如果待迁移的 Storage 节点中有多个图空间的分片,需要分别在每个图空间内执行该命令以迁移该 Storage 节点中的所有分片。
-
Storage 的扩容:在新机器上准备 Storage 二进制文件和配置文件,在配置文件中修改或增加已在运行的 Meta 地址,然后注册 Storage 到 Meta 并启动 Storage 进程。详情参见注册 Storage 服务。
Storage 扩缩容之后,根据需要执行
SUBMIT JOB BALANCE DATA将当前图空间的分片平均分配到所有 Storage 节点中和执行SUBMIT JOB BALANCE LEADER命令均衡分布所有图空间中的 leader。运行命令前,需要选择一个图空间。
-
如何在 Storage 节点中增加或减少磁盘¶
目前,Storage 不支持动态识别新的磁盘。可以通过以下步骤在分布式集群的 Storage 节点中增加或减少磁盘(不支持对单个 Storage 节点的集群增加或减少磁盘):
-
执行
SUBMIT JOB BALANCE DATA REMOVE <ip:port>将待增加或减少磁盘的 Storage 节点迁到其他 Storage 节点中。Caution
- 执行该命令迁移指定 Storage 节点中的分片数据前,需要确保其他 Storage 节点数量足够以满足设置的副本数。例如,如果设置了副本数为 3,那么在执行该命令前,需要确保其他 Storage 节点数量大于等于 3。
- 如果待迁移的 Storage 节点中有多个图空间的分片,需要分别在每个图空间内执行该命令以迁移该 Storage 节点中的所有分片。
-
执行
DROP HOSTS <ip:port>移除待增加或减少磁盘的 Storage 节点。 -
在所有 Storage 节点配置文件中通过
--data_path配置新增或减少磁盘路径,详情参见 Storage 配置文件。 - 执行
ADD HOSTS <ip:port>重新添加待增加或减少磁盘的 Storage 节点。 - 根据需要执行
SUBMIT JOB BALANCE DATA将当前图空间的分片平均分配到所有 Storage 节点中和执行SUBMIT JOB BALANCE LEADER命令均衡分布所有图空间中的 leader。运行命令前,需要选择一个图空间。