集群间数据同步¶
Nebula Graph 支持在集群间进行数据同步,即主集群 A 的数据可以近实时地复制到从集群 B 中,方便用户进行异地灾备或分流,降低数据丢失的风险,保证数据安全。
Enterpriseonly
仅企业版支持本功能。
背景¶
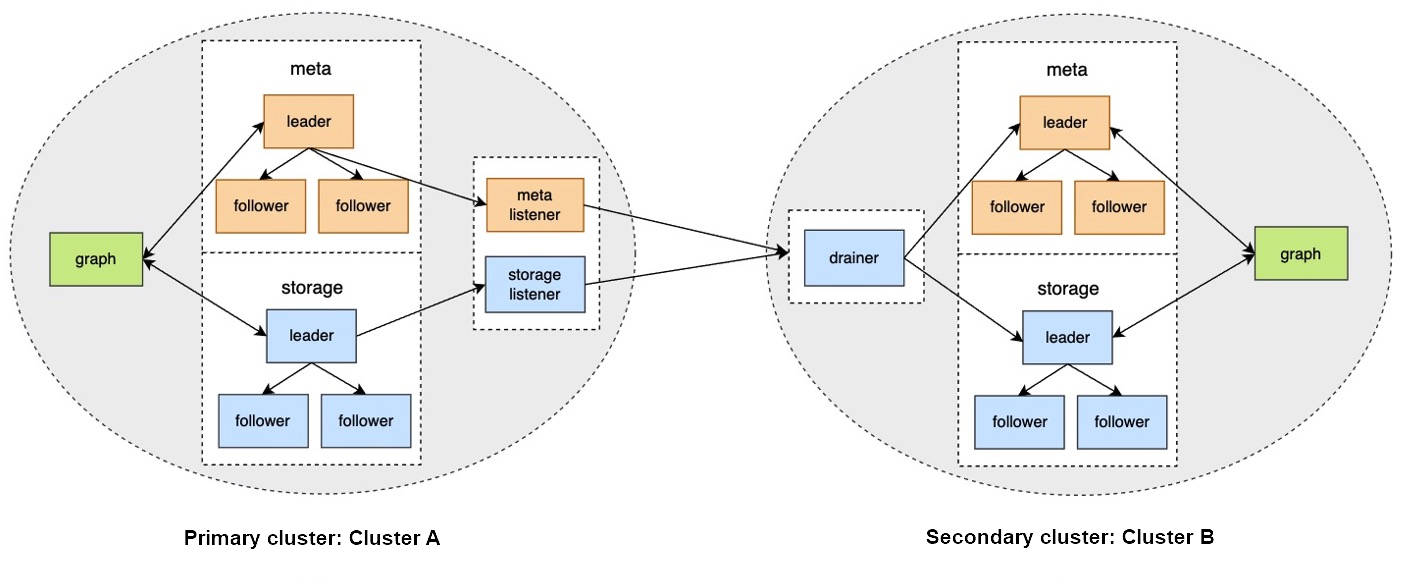
在集群间数据同步方案中,如果主集群 A 的图空间 a 和从集群 B 的图空间 b 建立了同步关系,任何向图空间 a 写入的数据,都会被发送到 Meta listener 或 Storage listener。listener 再将数据发送到 drainer。drainer 接收并存储数据,然后通过从集群的 Meta client 或 Storage client 发送数据至从集群的对应分片。
通过以上流程,最终实现集群间数据同步。
适用场景¶
- 异地灾备:通过数据同步可以实现跨机房或者跨城市的异地灾备。
- 数据迁移:通过切换主从集群的身份,可以实现不停止服务而完成迁移。
- 读写分离:通过设置主集群只写,从集群只读,实现读写分离,降低集群负载,提高稳定性和可用性。
注意事项¶
- 数据同步的基本单位是图空间,即只可以设置从一个图空间到另一个图空间的数据同步。
- 主从集群的数据同步是异步的(近实时)。
- 不支持多个主集群同步到 1 个从集群,只支持 1 对 1。
操作步骤¶
准备工作¶
- 准备至少 2 台部署服务的机器。主从集群需要分开部署,listener 和 drainer 可以单独部署,也可以分别部署在主从集群所在机器上,但是会增加集群负载。
- 准备企业版 License 文件。
示例环境¶
主集群A:机器 IP 地址为192.168.10.101,只启动 Graph、Meta、Storage 服务。
从集群B:机器 IP 地址为192.168.10.102,只启动 Graph、Meta、Storage 服务。
listener:机器 IP 地址为192.168.10.103,只启动 Meta listener、Storage listener 服务。
drainer:机器 IP 地址为192.168.10.104,只启动 drainer 服务。
1.搭建主从集群、listener 和 drainer 服务¶
-
在所有机器上安装 Nebula Graph,修改配置文件:
- 主、从集群修改:
nebula-graphd.conf、nebula-metad.conf、nebula-storaged.conf。
- listener 修改:
nebula-metad-listener.conf、nebula-storaged-listener.conf。
- drainer 修改:
nebula-drainerd.conf。
Note
修改配置文件时,必须修改的参数如下:
- 所有配置文件里都需要用真实的机器 IP 地址替换
local_ip的127.0.0.1。- 所有
nebula-graphd.conf配置文件里设置enable_authorize=true。- 主从集群填写各自的
meta_server_addrs。- listener 的配置文件里
meta_server_addrs填写主集群的机器 IP,meta_sync_listener填写 listener 机器的 IP。- drainer 的配置文件里
meta_server_addrs填写从集群的机器 IP。更多配置说明,请参见配置管理。
- 主、从集群修改:
-
在主从集群和 listener 服务的机器上放置 License 文件,路径为安装目录的
share/resources/内。 -
在所有机器的 Nebula Graph 安装目录内启动对应的服务:
- 主、从集群启动命令:
sudo scripts/nebula.service start all。
-
listener 启动命令:
- Meta listener:
sudo bin/nebula-metad --flagfile etc/nebula-metad-listener.conf。
- Storage listener:
sudo bin/nebula-storaged --flagfile etc/nebula-storaged-listener.conf。
- Meta listener:
- drainer 启动命令:
sudo scripts/nebula-drainerd.service start。
- 主、从集群启动命令:
-
登录主集群增加 Storage 主机,检查 listener 服务状态。
nebula> ADD HOSTS 192.168.10.101:9779; nebula> SHOW HOSTS STORAGE; +------------------+------+----------+-----------+--------------+----------------------+ | Host | Port | Status | Role | Git Info Sha | Version | +------------------+------+----------+-----------+--------------+----------------------+ | "192.168.10.101" | 9779 | "ONLINE" | "STORAGE" | "xxxxxxx" | "ent-3.1.0" | +------------------+------+----------+-----------+--------------+----------------------+ nebula> SHOW HOSTS STORAGE LISTENER; +------------------+------+----------+--------------------+--------------+----------------------+ | Host | Port | Status | Role | Git Info Sha | Version | +------------------+------+----------+--------------------+--------------+----------------------+ | "192.168.10.103" | 9789 | "ONLINE" | "STORAGE_LISTENER" | "xxxxxxx" | "ent-3.1.0" | +------------------+------+----------+--------------------+--------------+----------------------+ nebula> SHOW HOSTS META LISTENER; +------------------+------+----------+-----------------+--------------+----------------------+ | Host | Port | Status | Role | Git Info Sha | Version | +------------------+------+----------+-----------------+--------------+----------------------+ | "192.168.10.103" | 9559 | "ONLINE" | "META_LISTENER" | "xxxxxxx" | "ent-3.1.0" | +------------------+------+----------+-----------------+--------------+----------------------+ -
登录从集群增加 Storage 主机,检查 drainer 服务状态。
nebula> ADD HOSTS 192.168.10.102:9779; nebula> SHOW HOSTS STORAGE; +------------------+------+----------+-----------+--------------+----------------------+ | Host | Port | Status | Role | Git Info Sha | Version | +------------------+------+----------+-----------+--------------+----------------------+ | "192.168.10.102" | 9779 | "ONLINE" | "STORAGE" | "xxxxxxx" | "ent-3.1.0" | +------------------+------+----------+-----------+--------------+----------------------+ nebula> SHOW HOSTS DRAINER; +------------------+------+----------+-----------+--------------+----------------------+ | Host | Port | Status | Role | Git Info Sha | Version | +------------------+------+----------+-----------+--------------+----------------------+ | "192.168.10.104" | 9889 | "ONLINE" | "DRAINER" | "xxxxxxx" | "ent-3.1.0" | +------------------+------+----------+-----------+--------------+----------------------+
2.设置服务¶
-
登录主集群,创建图空间
basketballplayer。nebula> CREATE SPACE basketballplayer(partition_num=15, replica_factor=1, vid_type=fixed_string(30)); -
进入图空间
basketballplayer,注册 drainer 服务。nebula> USE basketballplayer; //注册 drainer 服务。 nebula> SIGN IN DRAINER SERVICE(192.168.10.104:9889); //检查是否注册成功。 nebula> SHOW DRAINER CLIENTS; +-----------+------------------+------+ | Type | Host | Port | +-----------+------------------+------+ | "DRAINER" | "192.168.10.104" | 9889 | +-----------+------------------+------+ -
设置 listener 服务。
//设置 listener 服务,待同步的图空间名称为replication_basketballplayer(下文将在从集群中创建)。 nebula> ADD LISTENER SYNC META 192.168.10.103:9559 STORAGE 192.168.10.103:9789 TO SPACE replication_basketballplayer; //查看 listener 状态。 nebula> SHOW LISTENER SYNC; +--------+--------+------------------------+--------------------------------+----------+ | PartId | Type | Host | SpaceName | Status | +--------+--------+------------------------+--------------------------------+----------+ | 0 | "SYNC" | ""192.168.10.103":9559" | "replication_basketballplayer" | "ONLINE" | | 1 | "SYNC" | ""192.168.10.103":9789" | "replication_basketballplayer" | "ONLINE" | | 2 | "SYNC" | ""192.168.10.103":9789" | "replication_basketballplayer" | "ONLINE" | | 3 | "SYNC" | ""192.168.10.103":9789" | "replication_basketballplayer" | "ONLINE" | | 4 | "SYNC" | ""192.168.10.103":9789" | "replication_basketballplayer" | "ONLINE" | | 5 | "SYNC" | ""192.168.10.103":9789" | "replication_basketballplayer" | "ONLINE" | | 6 | "SYNC" | ""192.168.10.103":9789" | "replication_basketballplayer" | "ONLINE" | | 7 | "SYNC" | ""192.168.10.103":9789" | "replication_basketballplayer" | "ONLINE" | | 8 | "SYNC" | ""192.168.10.103":9789" | "replication_basketballplayer" | "ONLINE" | | 9 | "SYNC" | ""192.168.10.103":9789" | "replication_basketballplayer" | "ONLINE" | | 10 | "SYNC" | ""192.168.10.103":9789" | "replication_basketballplayer" | "ONLINE" | | 11 | "SYNC" | ""192.168.10.103":9789" | "replication_basketballplayer" | "ONLINE" | | 12 | "SYNC" | ""192.168.10.103":9789" | "replication_basketballplayer" | "ONLINE" | | 13 | "SYNC" | ""192.168.10.103":9789" | "replication_basketballplayer" | "ONLINE" | | 14 | "SYNC" | ""192.168.10.103":9789" | "replication_basketballplayer" | "ONLINE" | | 15 | "SYNC" | ""192.168.10.103":9789" | "replication_basketballplayer" | "ONLINE" | +--------+--------+------------------------+--------------------------------+----------+ -
登录从集群,创建图空间
replication_basketballplayer。nebula> CREATE SPACE replication_basketballplayer(partition_num=15, replica_factor=1, vid_type=fixed_string(30)); -
进入图空间
replication_basketballplayer,设置 drainer 服务。//设置 drainer 服务。 nebula> ADD DRAINER 192.168.10.104:9889; //查看 drainer 状态。 nebula> SHOW DRAINERS; +-------------------------+----------+ | Host | Status | +-------------------------+----------+ | ""192.168.10.104":9889" | "ONLINE" | +-------------------------+----------+ -
修改图空间为只读。
Note
修改为只读是防止误操作导致数据不一致。只影响该图空间,其他图空间仍然可以读写。
nebula> USE replication_basketballplayer; //设置当前图空间为只读。 nebula> SET VARIABLES read_only=true; //查看当前图空间的读写属性。 nebula> GET VARIABLES read_only; +-------------+--------+-------+ | name | type | value | +-------------+--------+-------+ | "read_only" | "bool" | true | +-------------+--------+-------+
3.验证数据¶
-
登录主集群,创建 Schema,插入数据。
nebula> USE basketballplayer; nebula> CREATE TAG player(name string, age int); nebula> CREATE EDGE follow(degree int); nebula> INSERT VERTEX player(name, age) VALUES "player100":("Tim Duncan", 42); nebula> INSERT VERTEX player(name, age) VALUES "player101":("Tony Parker", 36); nebula> INSERT EDGE follow(degree) VALUES "player101" -> "player100":(95); -
登录从集群,检查数据。
nebula> USE replication_basketballplayer; nebula> SUBMIT JOB STATS; nebula> SHOW STATS; +---------+------------+-------+ | Type | Name | Count | +---------+------------+-------+ | "Tag" | "player" | 2 | | "Edge" | "follow" | 1 | | "Space" | "vertices" | 2 | | "Space" | "edges" | 1 | +---------+------------+-------+ nebula> FETCH PROP ON player "player100" YIELD properties(vertex); +-------------------------------+ | properties(VERTEX) | +-------------------------------+ | {age: 42, name: "Tim Duncan"} | +-------------------------------+ nebula> GO FROM "player101" OVER follow YIELD dst(edge); +-------------+ | dst(EDGE) | +-------------+ | "player100" | +-------------+
切换主从集群¶
如果因为业务需要进行数据迁移,或者灾备恢复后需要切换主从集群,需要手动进行切换。
Note
在切换主从之前需要为新的主集群搭建并启动 listener 服务(示例 IP 为192.168.10.105),为新的从集群搭建并启动 drainer 服务(示例 IP 为192.168.10.106)。
-
登录主集群,取消 drainer 和 listener 服务。
nebula> USE basketballplayer; nebula> SIGN OUT DRAINER SERVICE; nebula> REMOVE LISTENER SYNC; -
设置图空间为只读,防止有新的数据写入主集群,导致数据不一致。
nebula> SET VARIABLES read_only=true; -
登录从集群,设置图空间为可读写,取消 drainer。
nebula> USE replication_basketballplayer; nebula> SET VARIABLES read_only=false; nebula> REMOVE DRAINER; -
将从集群更改为主集群。
nebula> SIGN IN DRAINER SERVICE(192.168.10.106:9889); nebula> ADD LISTENER SYNC META 192.168.10.105:9559 STORAGE 192.168.10.105:9789 TO SPACE basketballplayer; nebula> REMOVE DRAINER; -
登录之前的主集群,将其更改为从集群。
nebula> USE basketballplayer; //修改图空间为可读写,否则无法设置 drainer 服务。 nebula> SET VARIABLES read_only=false; nebula> ADD DRAINER 192.168.10.106:9889; nebula> SET VARIABLES read_only=true;
常见问题¶
主集群中已经有一部分存量数据了,从集群可以同步到之前的存量数据吗?¶
可以。drainer 接收到 listener 的 WAL 后,如果发现从集群中没有待修改的数据,会从 listener 中拉取全量数据并覆盖到从集群中的相应分片。
从集群中已经有数据了,数据同步会有影响吗?¶
如果从集群中的数据是主集群中的数据的子集,通过数据同步最终会实现数据一致。
如果主集群中没有从集群中的部分数据,通过数据同步最终不会实现数据一致,因为不一致的数据仍然存在于从集群中,需要 DBA 评估下这些差异数据是否需要保留。
从集群中已经有 Schema 了,数据同步会有影响吗?¶
需要 DBA 确保从集群中的 Schema 和主集群中的 Schema 没有冲突,否则数据同步时主集群中的 Schema 会覆盖从集群中的 Schema,可能导致被覆盖的 Schema 对应的数据失效。
主从集群的机器数量、副本数量、分片数量需要相同吗?¶
不需要。因为是以图空间为基本单位,主集群不需要知道从集群的架构信息,只需要将 WAL 发送给 listener 即可。
修改 Schema 会影响数据同步吗?¶
可能会增加数据同步延迟。因为 Schema 数据和普通数据是分开处理的(Meta listener 和 Storage listener),普通数据同步时会检查自身的 Schema 版本,如果版本大于当前存储的版本,说明 Schema 有更新,这时候会暂缓更新,等待 Schema 数据先更新完成。
如何判断数据同步进度?¶
可以通过比较当前正在同步的 WAL 的时间戳和最新的 WAL 的时间戳,从而判断数据同步是否正常,也可以自行实现对进度的监控。